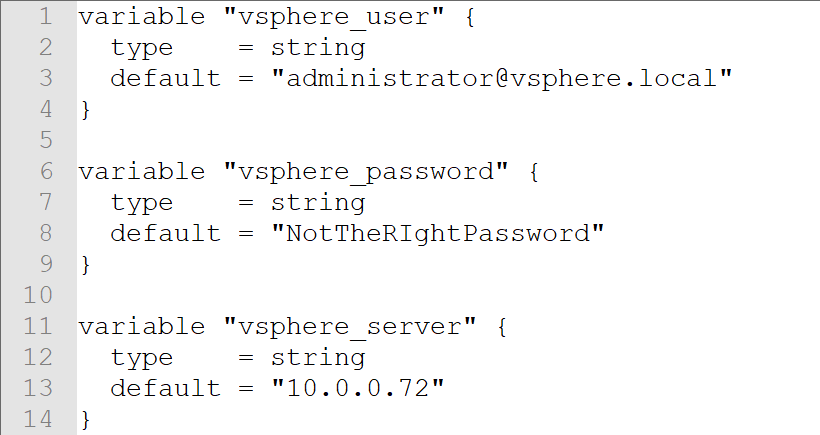
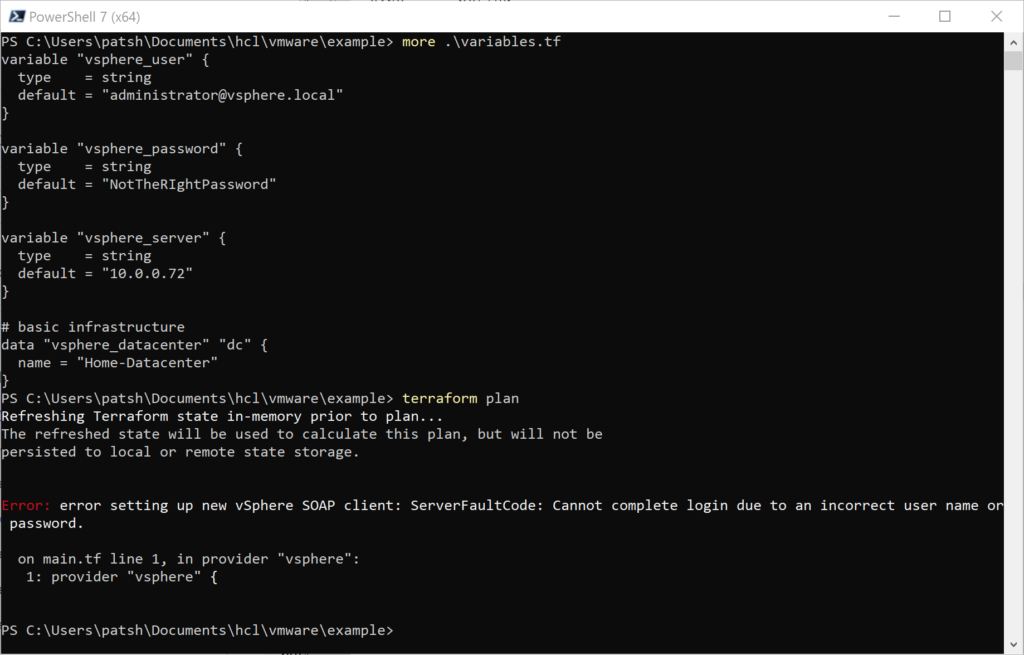
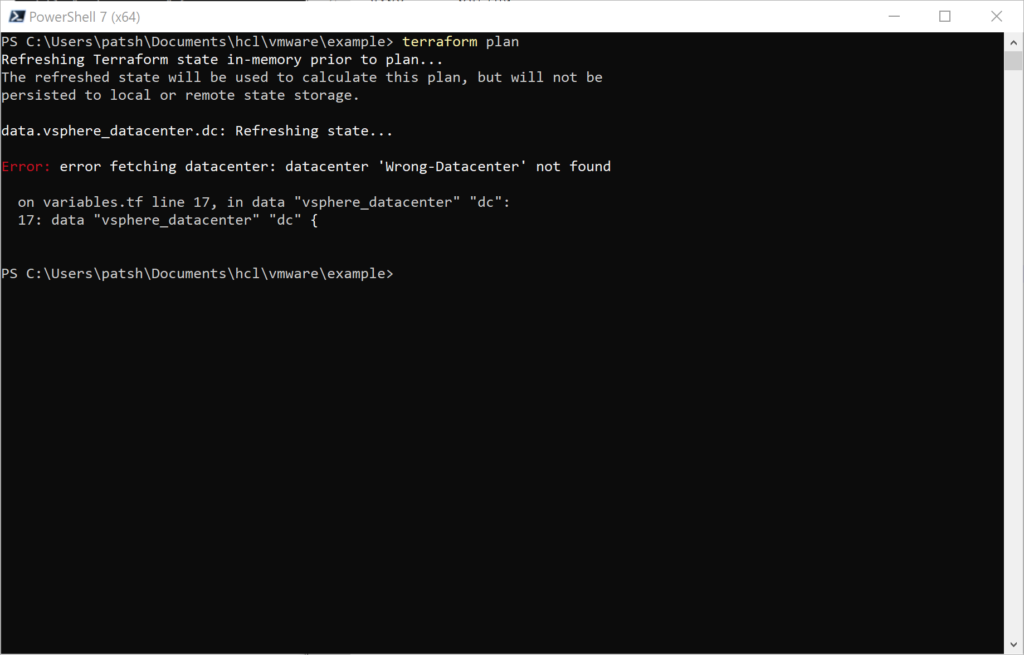
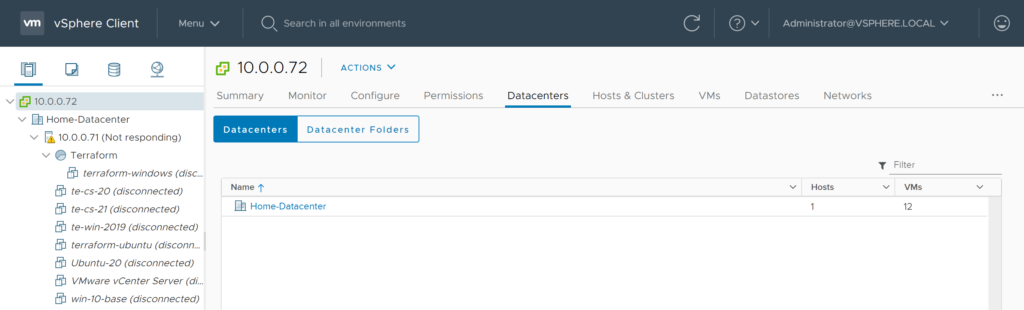
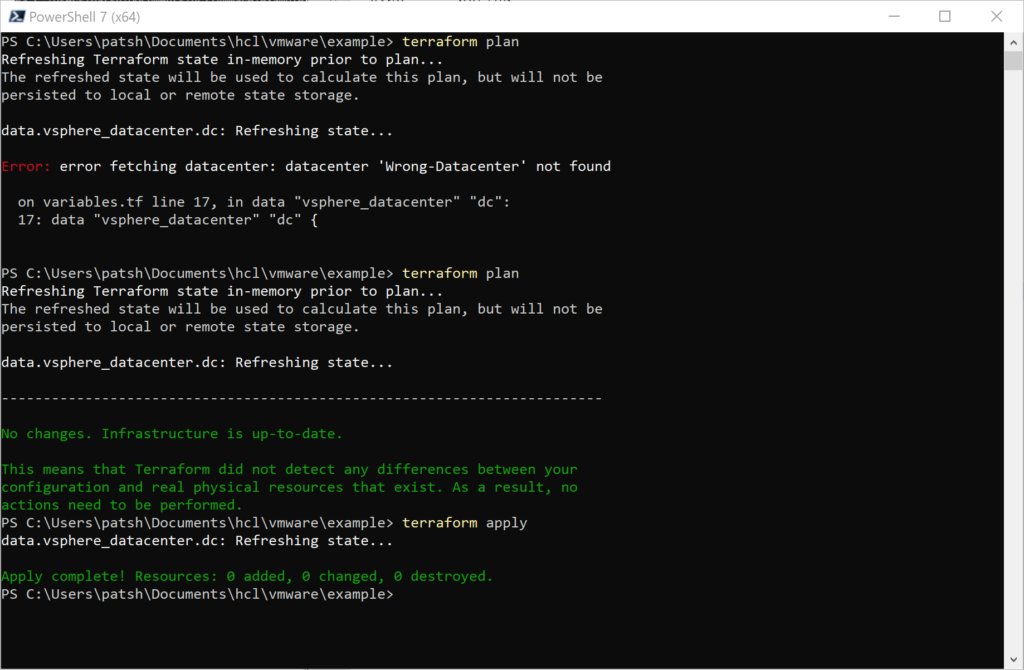
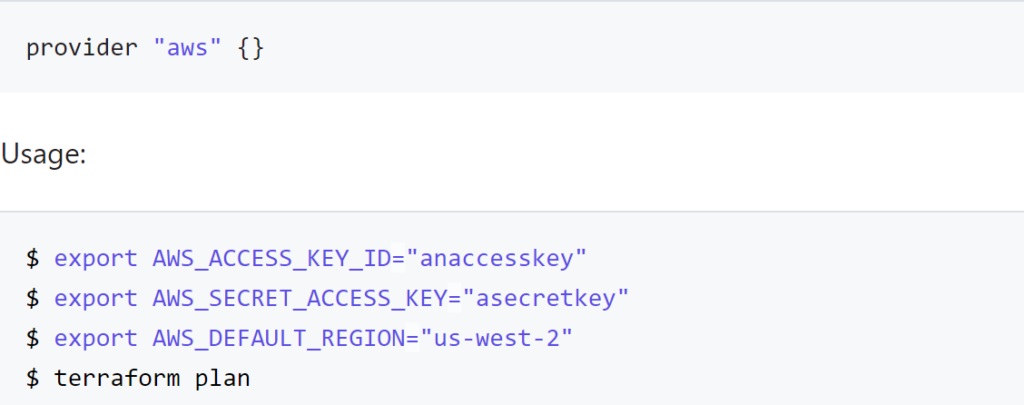
In our previous blog we talked about provisioning an AWS Provider into Terraform. It was important to note that it differed from the vSphere provider in that you can create multiple AWS providers for different regions and give an alias to each region or login credentials as desired. With vSphere you can only have one provider and no aliases.
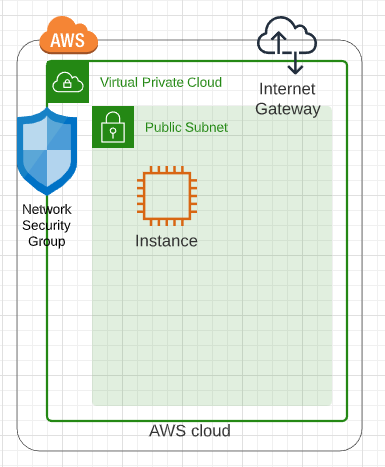
Once we have a provider defined we need to create elements inside the provider. If our eventual goal is to create a database using software as a service or a virtual machine using infrastructure as a service then we need to create a network to communicate with these services. With AWS there are basically two layers of network that you can define and two components associated with these networks.
The first layer is the virtual private network which defines an address range and access rights into the network. The network can be completely closed and private. The network can be an extension of your existing datacenter through a virtual private network connection. The network can be an isolated network that has public access points allowing clients and consumers access to websites and services hosted in AWS.
Underneath the virtual private network is either a public or private subnet that segments the IP addresses into smaller chunks and allows for instances to be addressed on the subnet network. Multiple subnet definitions can be created inside a virtual private network to segment communications with the outside world and private communications between servers (for example a database server and applications server). The application server might need a public IP address and an private IP address while the database server typically will only have a private IP address.
Associated with the network and subnets are a network security group and internet gateway to restrict access to servers in the AWS cloud. A diagram of this configurations with a generic compute instance is shown below.
The first element that needs to be defined is the AWS Provider.
provider “aws” {
version = “> 2”
profile = “default”
region = “us-east-1”
alias = “east”
}
The second component would be the virtual private cloud or aws_vpc.
resource “aws_vpc” “myNet” {
cidr_block = “10.0.0.0/16”
provider = aws.east
tags = {
Name = “myNet”
environment = var.environment
createdby = var.createdby
}
}
Note that the only required attribute for the aws_vpc is the cidr_block. Everything else is optional. It is important to note that the aws_vpc can be defined as a resource or as a data element that does not create or destroy the network definition in AWS with terraform apply and destroy. With the data declaration the cidr_block is optional given that it has already been defined and the only only attribute needed to match the existing VPC is the name or the ID of the existing VPC.
Once the VPC has been created an aws_subnet can be defined and the two required elements for a resource definition are the cidr_block and the vpc_id. If you want to define the aws_subnet as a data element the only required resource is the vpc_id.
resource “aws_subnet” “MySubnet” {
provider = aws.east
vpc_id = aws_vpc.myNet.id
cidr_block = “10.0.1.0/24”
tags = {
Name = “MySubnet”
environment = var.environment
createdby = var.createdby
}
}
The provider declaration is not required but does help with debugging and troubleshooting at a later date. It is important to note that the VPC was defined with a /16 cidr_block and the subnet was a more restrictive /24 cidr_block. If we were going to place a database in a private network we would create another subnet definition and use a different cidr_block to isolate the network.
Another element that needs to be defined is an aws_internet_gateway to define access from one network (public or private) to another network. The only required element that is needed for the resource declaration is the internet gateway id. If you define the aws_internet_gateway as a data declaration then the name or the vpc_id is required to map to an existing gateway declaration.
resource “aws_internet_gateway” “igw” {
provider = aws.aws
vpc_id = aws_vpc.myNet.id
tags = {
Name = “igw”
environment = var.environment
createdby = var.createdby
}
}
The final element that we want to define is the network security group which defines ports that are open inbound and outbound. In the following example we define inbound rules for ports 80, 443, and 8400-8403, ssh (port 22), and rdp (port 3389) as well as outbound traffic for all ports.
resource “aws_security_group” “cmvltRules” {
provider = aws.aws
name = “cmvltRules”
description = “allow ports 80, 443, 8400-8403 inbound traffic”
vpc_id = aws_vpc.myNet.id
ingress {
description = “Allow 443 from anywhere”
from_port = 443
to_port = 443
protocol = “tcp”
cidr_blocks = [“0.0.0.0/0”]
}
ingress {
description = “Allow 80 from anywhere”
from_port = 80
to_port = 80
protocol = “tcp”
cidr_blocks = [“0.0.0.0/0”]
}
ingress {
description = “Allow 8400-8403 from anywhere”
from_port = 8400
to_port = 8403
protocol = “tcp”
cidr_blocks = [“0.0.0.0/0”]
}
ingress {
description = “Allow ssh from anywhere”
from_port = 22
to_port = 22
protocol = “tcp”
cidr_blocks = [“0.0.0.0/0”]
}
ingress {
description = “Allow rdp from anywhere”
from_port = 3389
to_port = 3389
protocol = “tcp”
cidr_blocks = [“0.0.0.0/0”]
}
egress {
description = “Allow all to anywhere”
from_port = 0
to_port = 0
protocol = “-1”
cidr_blocks = [“0.0.0.0/0”]
}
tags = {
Name = “cmvltRules”
environment = var.environment
createdby = var.createdby
}
}
For the security group the protocol and from_port are the only required definitions when defining an aws_security_group resource. If you declare an aws_security_group data declaration then the name is the only required element. For the declaration shown above the provider and vpc_id to help identify the network that the roles are associated with for debugging and troubleshooting.
This simple video looks at the AWS console to see the changes defined by terraform using the main.tf and network.tf files saved in github.com.
In summary, network definitions on AWS are radically different and more secure than a typical vSphere provider definition with undefined network configurations. Understanding network configurations in Terraform help build a more predictable and secure deployment in the cloud. If you are part of a larger organization you might need to use data declarations rather than resource declarations unless you are creating your own sandbox. You might need to join a corporate VPC or dedicated subnet assigned to your team. Once networking is defined, new and creating things like moving dev/test to the cloud or testing database as a service to reduce license costs. The only step missing from these configuration files are setting up the aws configure and authentication using the AWS CLI interface. Terraform does a good job leveraging the command line authentication so that the public and private keys don’t need to be stored in files or configuration templates.