In my last two blog posts covering Groups and Roles, the recommendation was to not use Terraform to initialize either of these features of Azure. If we step back and look at what Terraform is good at and what Azure is good at we recognize that the two don’t overlap. Terraform is good at creating infrastructure from a definition. If you have a project that you need to build, Terraform is very good at wrapping everything into a neat package and provides the constructs to create, update, and destroy everything. They key work here is everything. If you have something that builds foundation above the project level and provides the foundation for multiple projects destruction of these constructs has reach beyond just a single project. Azure is also very good at creating a boundary around projects as we will see with Resource Groups but also has tools to build resources above the project layer that cross multiple projects. Roles and Groups are two examples of this higher layer. You might create a database administrator group or a secure network connection back to your on-premises datacenter that helps with reliability and security of all projects. Unfortunately, defining these terms in a Terraform project could potentially ruin other projects that rely upon a user or group or role existing. Rather than defining a resource to create users, groups, or roles it was suggested that a local-exec script be called to first test if the necessary definitions exist then create them if needed. The script would then avoid deletion during the destroy phase and not re-create the resource or error out if the resource did not exist. An exec script would allow for conditional testing and creating of these elements on the first execution and only on the first execution. Consider the case where you have a development workspace and a production workspace. There is no need to create a new role or a new group in Azure specific to that workspace. There is a need to create a new resource group and network definition but not a new set of users, groups and roles.

Using the diagram from the Microsoft documentation, creation of a tenant (Management group) or subscription does not make sense. Creating of a Resource group and Resources in Terraform is where the two fit perfectly. Consider the example of a three tiered architecture with virtual machines and web apps running in one resource group and a database running in another resource group. An alternate way of creating this is to create multiple subnets or virtual private networks and put everything in one resource group.
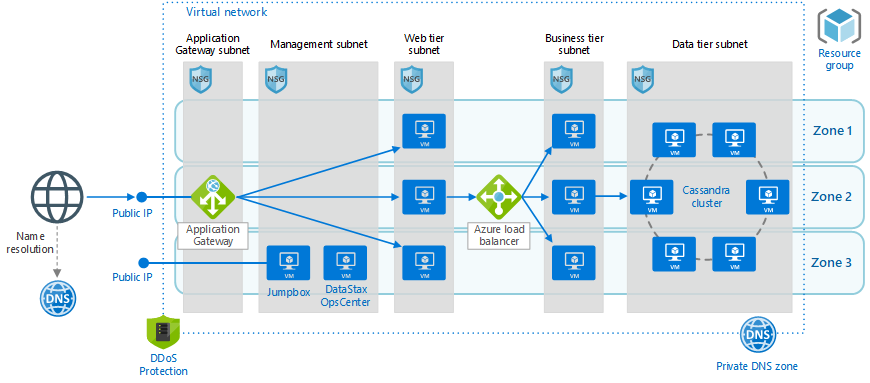
Note that we have one resource group, one virtual private network, a web tier on one subnet and a business and data tier on their own subnets. These deployments can cross multiple zones and all get wrapped with firewalls, network security rules, and DDoS protection. A simpler network configuration using SQL Server might look like the following diagram.
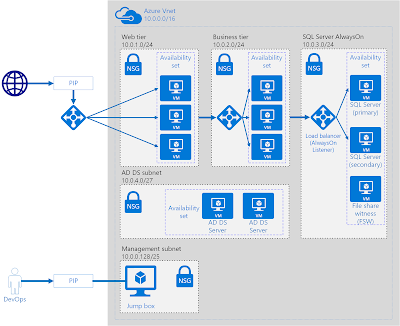
We create one resource group, one virtual network, five subnets in the same vnet, five network security groups, and three public IP addresses. Each subnet will contain an availability set that can scale with multiple virtual machines and have a load balancer where appropriate to communicate outside the subnet to other subnets or the public internet.
An Azure Resource Group can easily be reference using the azurerm_resource_group data declaration or the azurerm_resource_group resource declaration. For the data declaration the only required field is the resource group name. For the resource declaration we also have to define the location or Azure region where the resource group will be located. You can define multiple resource groups in different regions as well as define multiple azurerm providers to associate billing with different cost centers. In the simple example above we might want to associate the Active Directory and Bastion (or Jump box) servers with the IT department and the rest of the infrastructure with the marketing or engineering departments. If this project were a new marketing initiative the management subnet and AD DS subnet might be data declarations because they are used across other projects. All other infrastructure components will be defined in a Terraform directory and created and destroyed as needed.
To declare a virtual network we can use the azurerm_virtual_network data declaration or azurerm_virtual_network resource declaration. The data declaration requires a name and resource group while the resource declaration needs an address space and region definition as well. Under the virtual network we can declare a subnet with the azurerm_subnet data declaration or azurerm_subnet resource declaration. The data declaration requires a name, resource group, and virtual network while the resource declaration also needs either an address prefix or prefixes to define the subnet. Once we have a subnet defined we can define an azurerm_network_security_group resource or data declaration and associate it with a subnet using the azurerm_subnet_network_group_association resource to map the security to our subnet. All of these declarations are relatively simple and help define and build a security layer around our application.
In a previous blog post we talked about how to perform networking with AWS. The constructs for Azure are similar but have a resource group layered on top of the networking component. For AWS we defined a aws provider then an aws_vpc to define our virtual network. Under this network we created an aws_subnet to define subnets. For AWS we defined an aws_security_group and associated it with our virtual network or vpc_id.
Azure works a little differently in that the azurerm_network_security_group is associated with an azurerm_subnet and not the azurerm_virtual_network.
provider "azurerm" {
features {}
}
resource "azurerm_resource_group" "example" {
name = "Simple_Example_Resource_Group"
location = "westus"
}
resource "azurerm_virtual_network" "example" {
name = "virtualNetwork1"
location = azurerm_resource_group.example.location
resource_group_name = azurerm_resource_group.example.name
address_space = ["10.0.0.0/16"]
}
resource "azurerm_subnet" "example" {
name = "testsubnet"
resource_group_name = azurerm_resource_group.example.name
virtual_network_name = azurerm_virtual_network.example.name
address_prefixes = ["10.0.1.0/24"]
}
resource "azurerm_network_security_group" "example" {
name = "acceptanceTestSecurityGroup1"
location = azurerm_resource_group.example.location
resource_group_name = azurerm_resource_group.example.name
security_rule {
name = "test123"
priority = 100
direction = "Inbound"
access = "Allow"
protocol = "Tcp"
source_port_range = "*"
destination_port_range = "*"
source_address_prefix = "*"
destination_address_prefix = "*"
}
}
resource "azurerm_subnet_network_security_group_association" "example" {
subnet_id = azurerm_subnet.example.id
network_security_group_id = azurerm_network_security_group.example.id
}
Overall, this is a relatively simple example. We could declare four more subnets, four more network security groups, and four more network security group associations. Each network security group would have different definitions and allow traffic from restricted subnets rather than a wildcard allowing all access from all servers and ports. Terraform is very clean when it comes to creating a nice and neat resource group package and cleaning up with the destroy command all of the resources and network definitions defined under the resource group. This sample main.tf file is shared on github and only requires that you run the following commands to execute
- open a PowerShell with the az cli enabled
- download the main.tf file from github
- az login
- terraform init
- terraform plan
- terraform apply
- terraform destroy
The plan and destroy are optional parameters. All of this can be done from cloud shell because Microsoft has preconfigure Terraform in the default cloud shell environment. All you need to do is upload the main.tf file to your cloud shell environment our mount a shared cloud storage and execute the init and apply commands.