Recently I have been working on my AWS Architect certification. Rather than just grinding through the training material and practice exams I thought I should actually build something and journal my process. I have done this internally for Commvault but wanted to do an external blog as well so that if I left Commvault I would have a copy of my notes.
The first step in building something is documenting the project including the goals, objectives, and components that will be needed. Initially I interviewed the person that I am building this project for and drew everything on paper (I know, old school). From there I transcribed it into an AWS architecture diagram using LucidChart.
The goal of the project is to take a zip file that is an aggregation of ECGs performed on student athletes and upload it into S3. Once the zip file is uploaded it kicks off a process that unzips the files and copies them to another folder inside the bucket. From here these files are copies to Dropbox and a notification is sent to one or more email boxes or text messages. From this notification a Cardiologist interprets the results and responds to the email or text. Once the response is received the interpreted files are transferred from Dropbox back into S3 and sorted according to the school that was screened. Students that were marked as low risk are stamped with a low risk label. Students that were marked needing a follow up or high risk are placed into a different folder for manual processing and a notification is sent via email and/or text requesting for manual intervention.
The first step in the process is taking a zip file that was uploaded into S3 and processing it. Fortunately we have the ability to launch processes when a file is uploaded into S3 with the Lambda functions. A good place to start learning about this is https://docs.aws.amazon.com/lambda/latest/dg/with-s3-example.html where the tutorial talks about how to create a Lambda function and tie it to changes to a specific bucket. This also required creating an IAM role that allows a Lambda function to read and write an S3 bucket.
Step 1) Create IAM Role. This id done by going to the IAM console and selecting Roles at the left of the screen. We want to click on the Create role blue button near the middle of the screen.
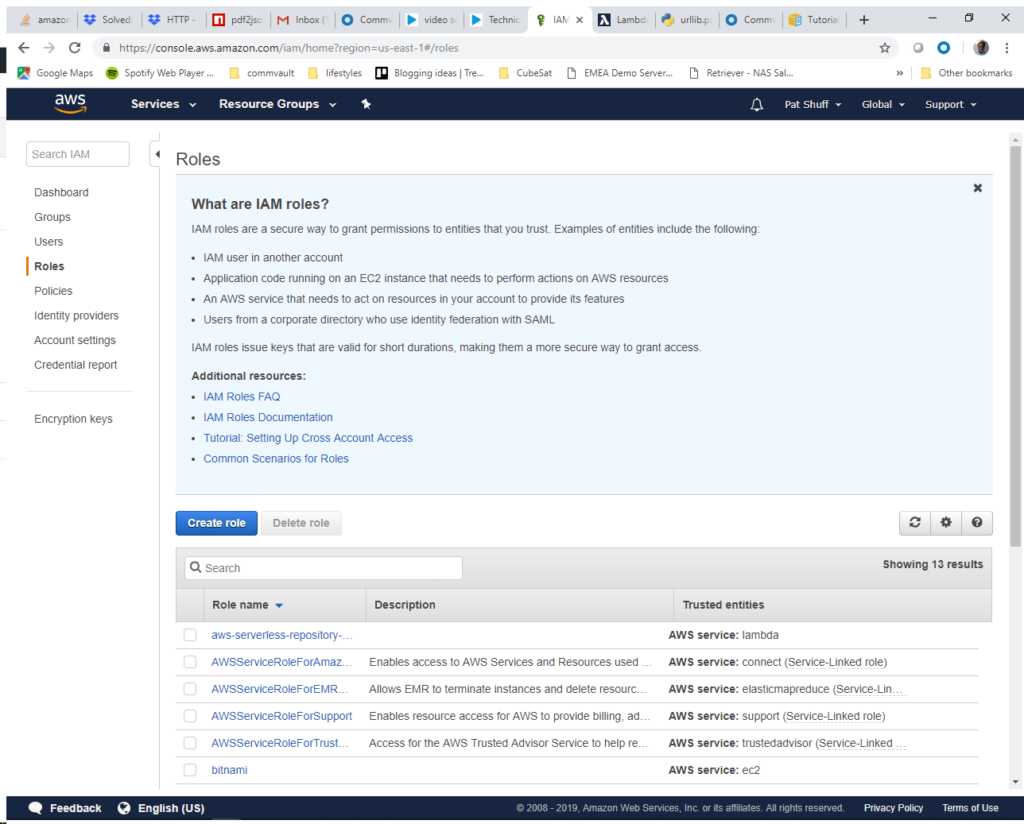
We select the Lambda function and click Next:Permissions at the bottom of the screen.
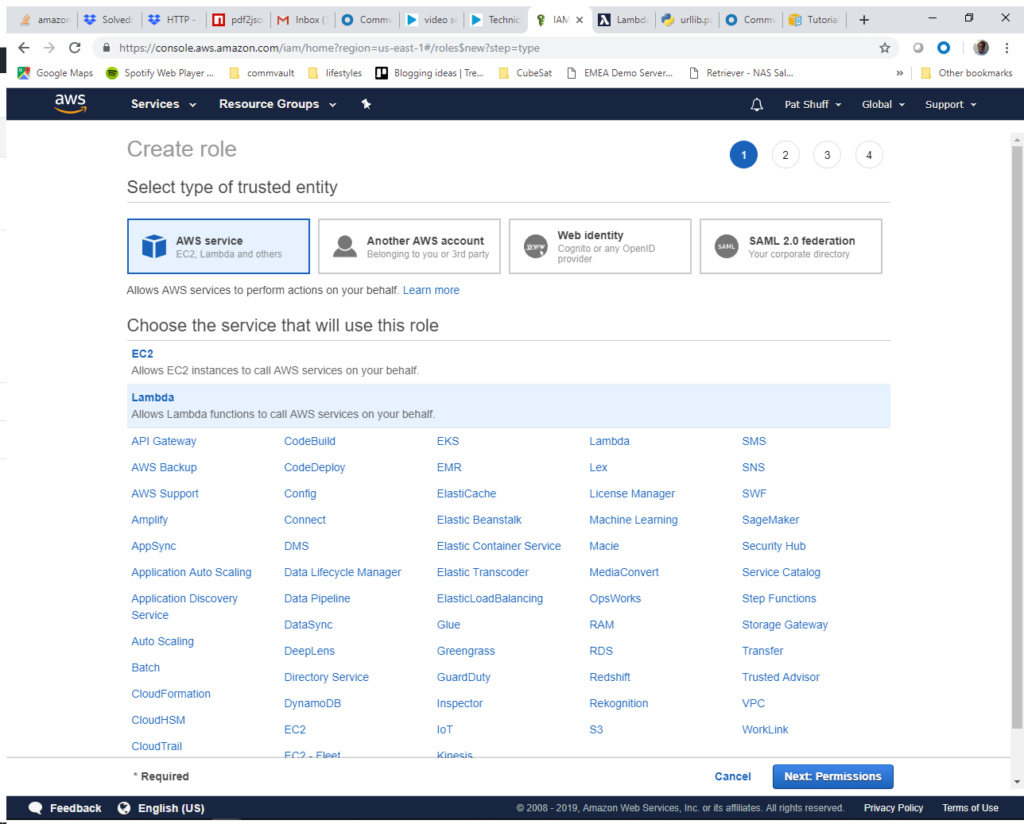
To make things easy we select AmazonS3FullAccess. What we want is the ability to read and write objects in an S3 bucket. We need to type in S3 in the Filter policies then select the box next to AmazonS3FullAccess.
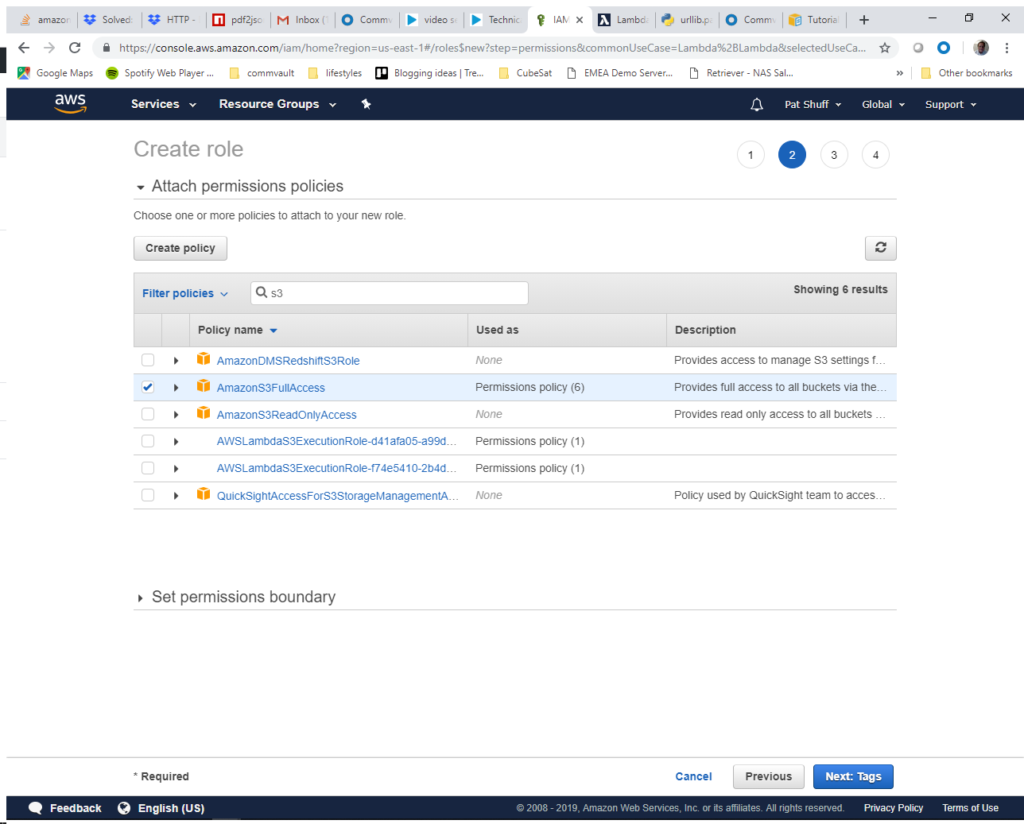
We skip the tags role and go to Review. Here we enter a Role name. We will call it gbgh-processing. Once we enter this information we click Create role at the bottom right of the screen.
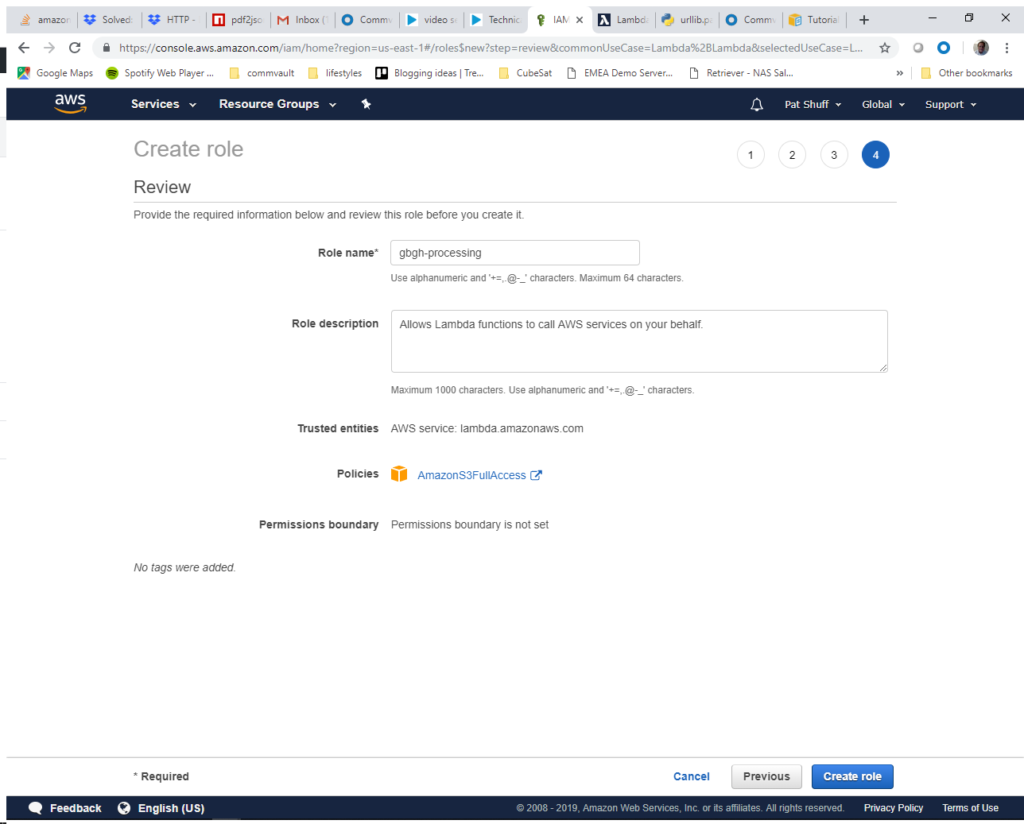
At this point we have a role that allows our Lambda function to access S3 objects and manipulate them.
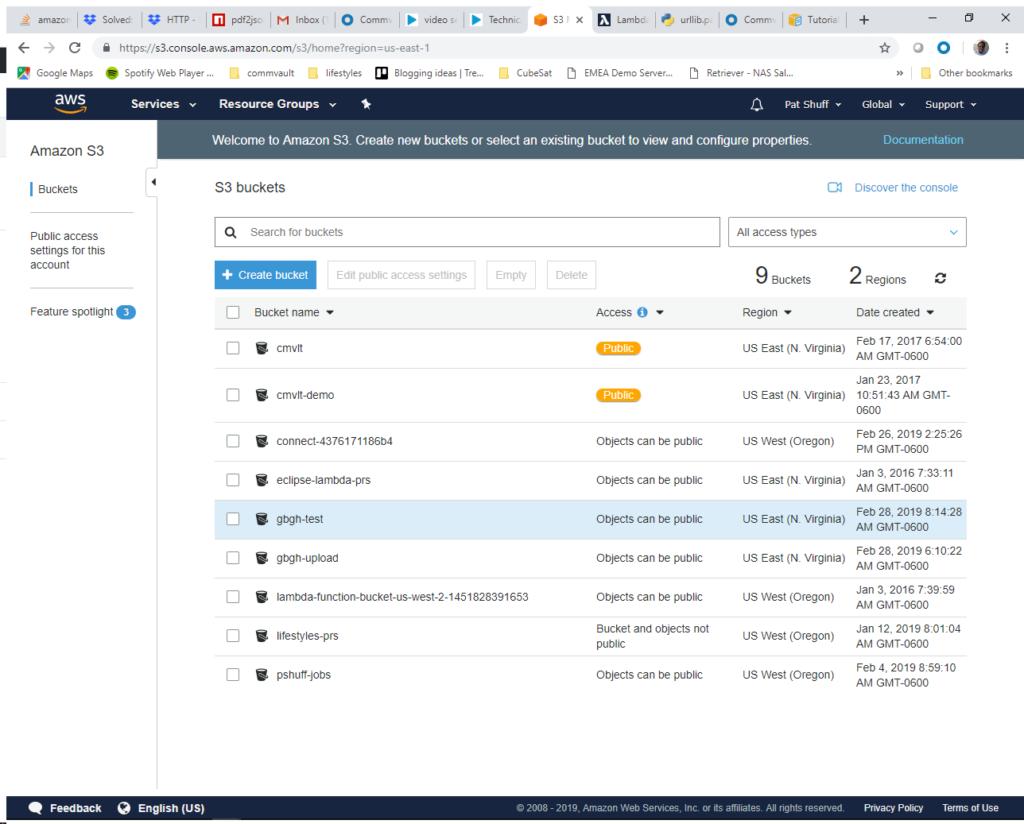
Step 2) The next step is to create a bucket that we will upload files into. This is done by going to the S3 console and creating a bucket. The bucket must be in the same zone that we create our Lambda function. In our example we will create a bucket called gbgh-test and put it in the US East region.
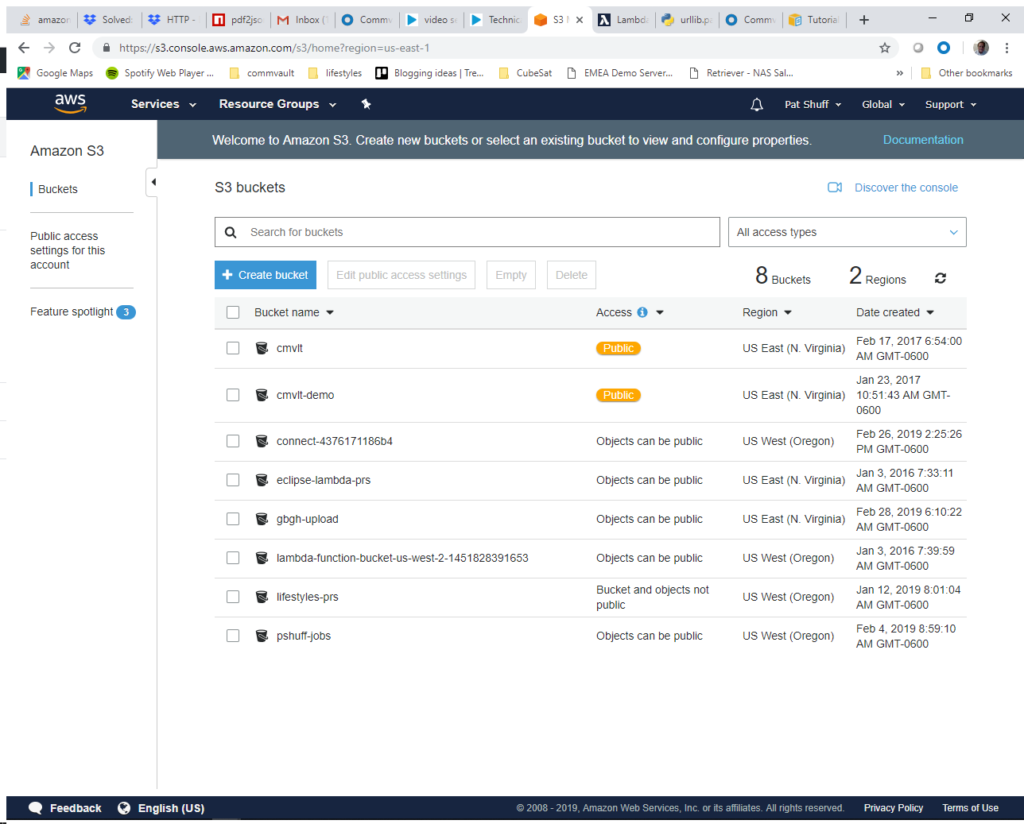
We click on the Create bucket blue button at the top left of the screen. The bucket name needs to be unique and we want the US East region. We don’t want to copy settings from other buckets and will configure the options on our own. We will be using gbgh-test as the bucket name.
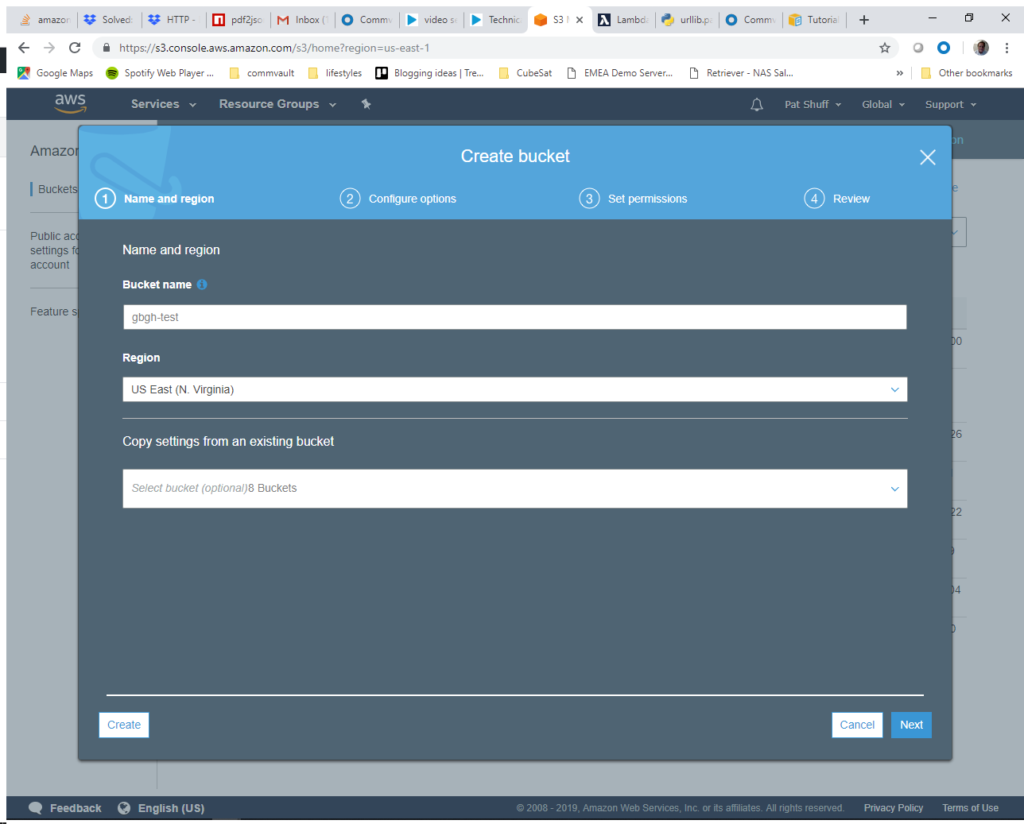
We will go with the default options and clear all of the permissions as shown below. We want to open up public access for our bucket because a variety of people long term will be uploading files into the bucket. We can control access through other mechanisms at a later date.
From here we click Next and Create Bucket on the next screen.
We should see our bucket ready and available in the S3 bucket list.
Step 3) create a Lambda function that receives S3 object changes so that we can process the files and do something with it. To do this we go to the Lambda function console.
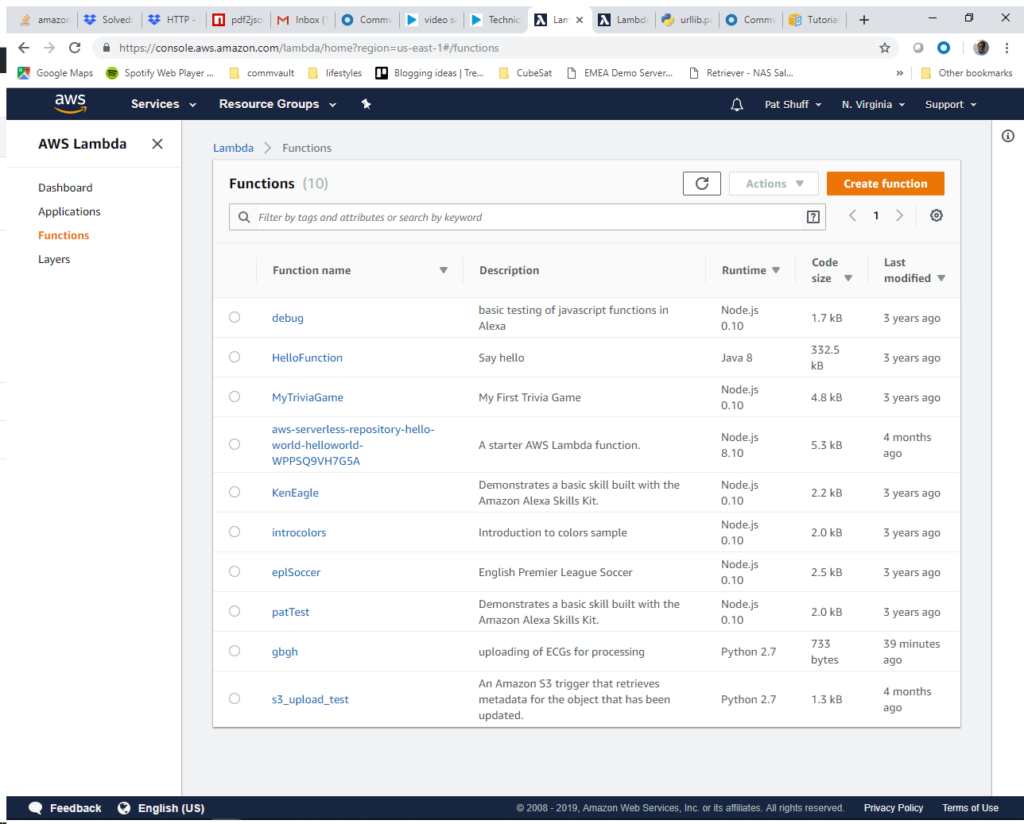
Notice that we have a few functions already defined. Some are Java. Some are Node.js. Some are Python. We will be creating a Python 2.7 binary so that we can use the boto3 library. This pre-defined library allows us to quickly and easily manipulate objects in a bucket and call other AWS services like email and queue services. To start we click on the orange Create function button at the top right of the screen.
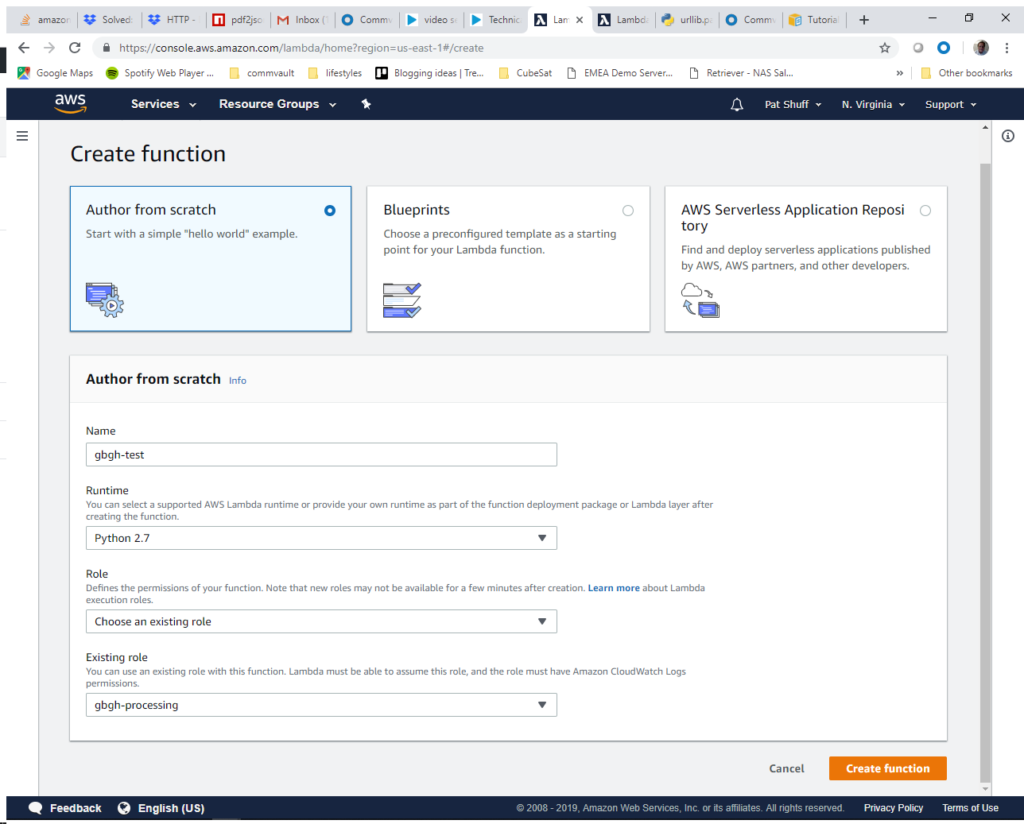
We will Author from scratch our code since we have some simple code that we can work from. We will call the function gbgh-test and select Python 2.7 as the runtime. We will select the gbgh-processing role to give our function access to the S3 bucket that we created.
When we click on the Create function it drops us into the Designer tool for editing and testing our Lambda function. The first thing that we want to do is add an S3 trigger to link S3 objects to our function.
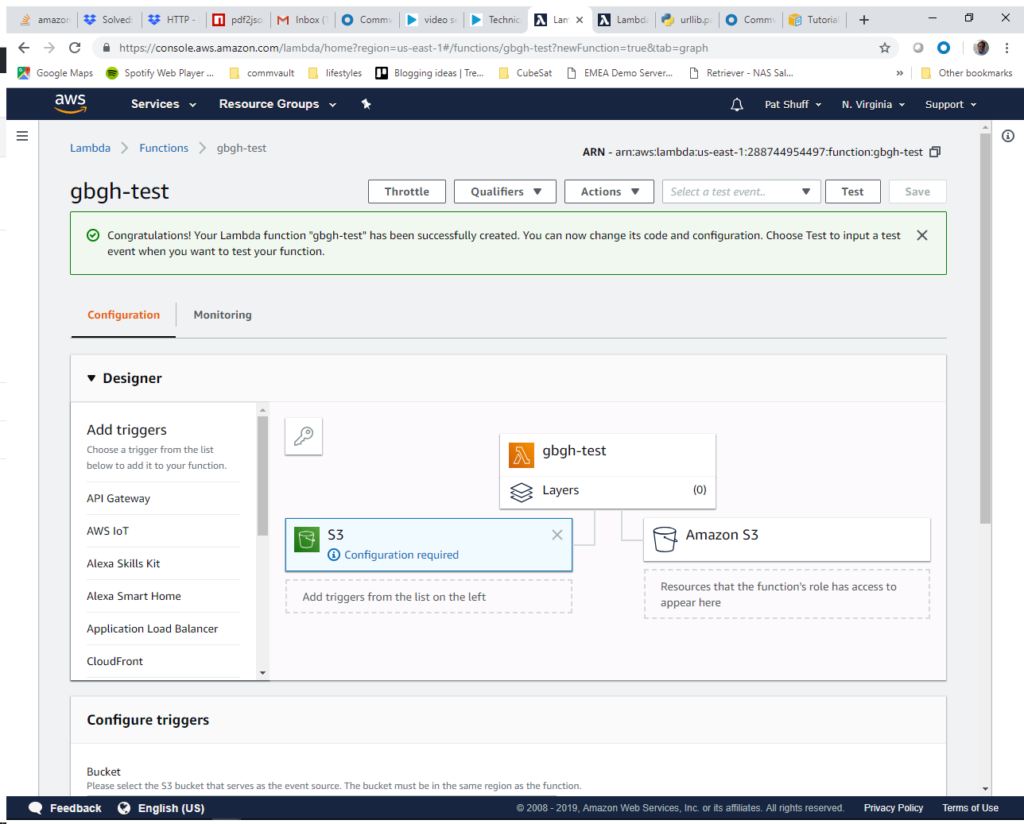
The trigger is found under the Designer – Add triggers list. Scroll down and click on S3. It will show that Configuration is required and we will need to scroll down to configure the trigger. From here we will select the bucket and Event type. We are looking for create events which indicates that someone uploaded a file for us to process. We select the gbgh-test bucket and stick with the All object create events.
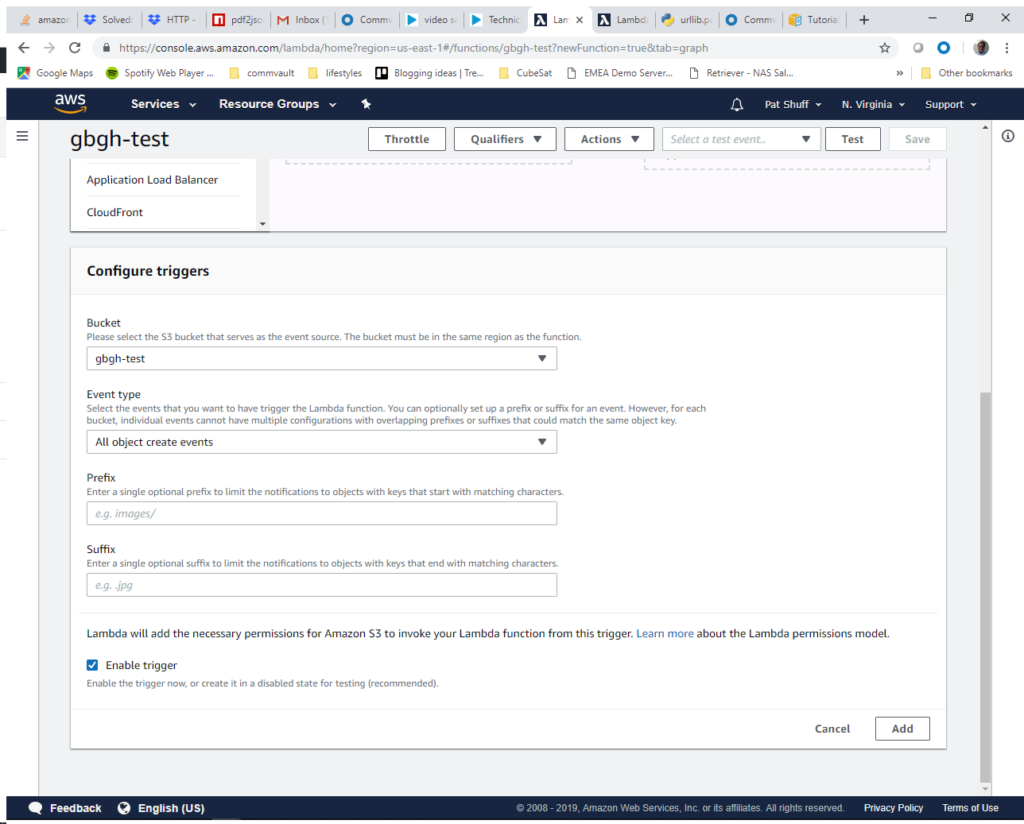
After clicking on Add we nativate to the gbgh-test icon to see the Function code where we can edit the function and test code that we want. The default handler does not do what we want so we need to replace this code.
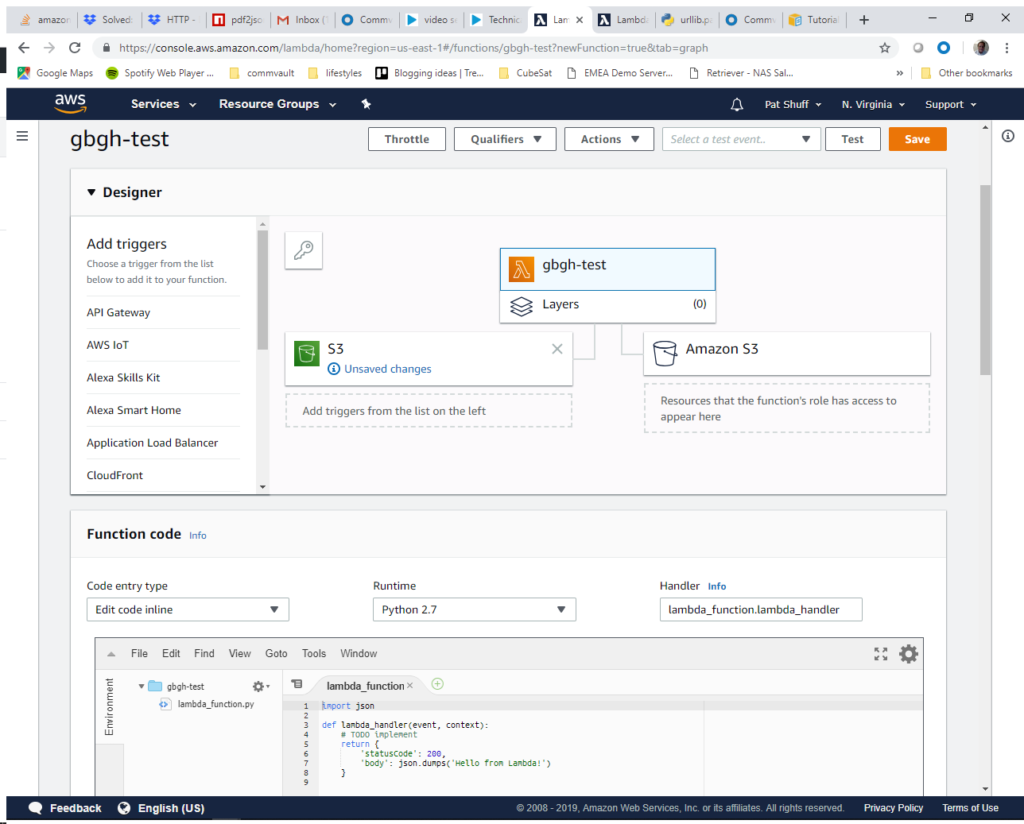
For our function we are going to start simple. We will handle a create event, pull the bucket name from the event handler, pull the file name that was uploaded, and print all of the items in the bucket for testing. The code starts with an import of the boto3 library. We create a handle into S3 with the boto3.resource(‘s3’) library call. The lambda_handler is launched when a file is created in our S3 bucket. From here we print some diagnostics that the handler was called then walk the object list in the bucket and print the object names. From here we return and terminate the Lambda function. Sample code for this can be found at lambda_function_s3_upload.js
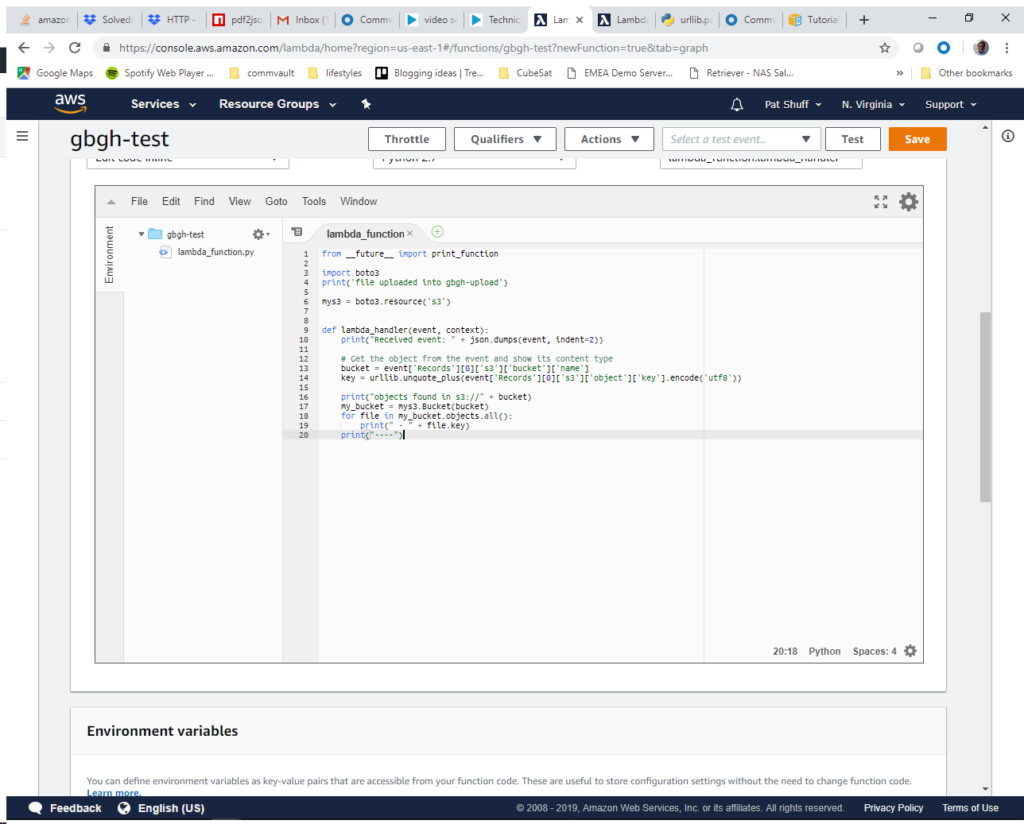
The next step is to create a test event to simulate a file upload. We do this by clicking on the Select a test event pulldown and selecting Configure test events.
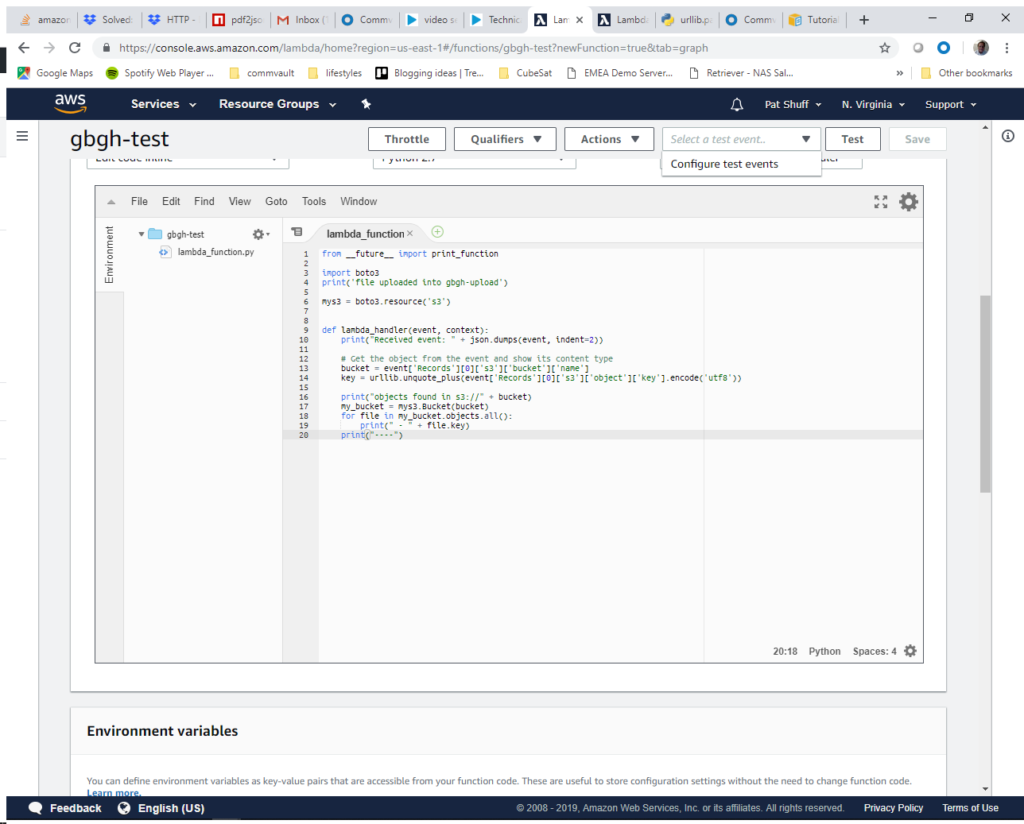
For the test event we need to simulate an ObjectCreated:Put call or an https PUT that causes a file to be uploaded to our S3 bucket. We need to define the arn for our bucket and bucket name as well as an object name (gbgh.zip) that we need to actually create in our gbgh-test bucket. We define the event name as gbghTest and paste in our simulated event call. The code for this can be found at testS3Put.json
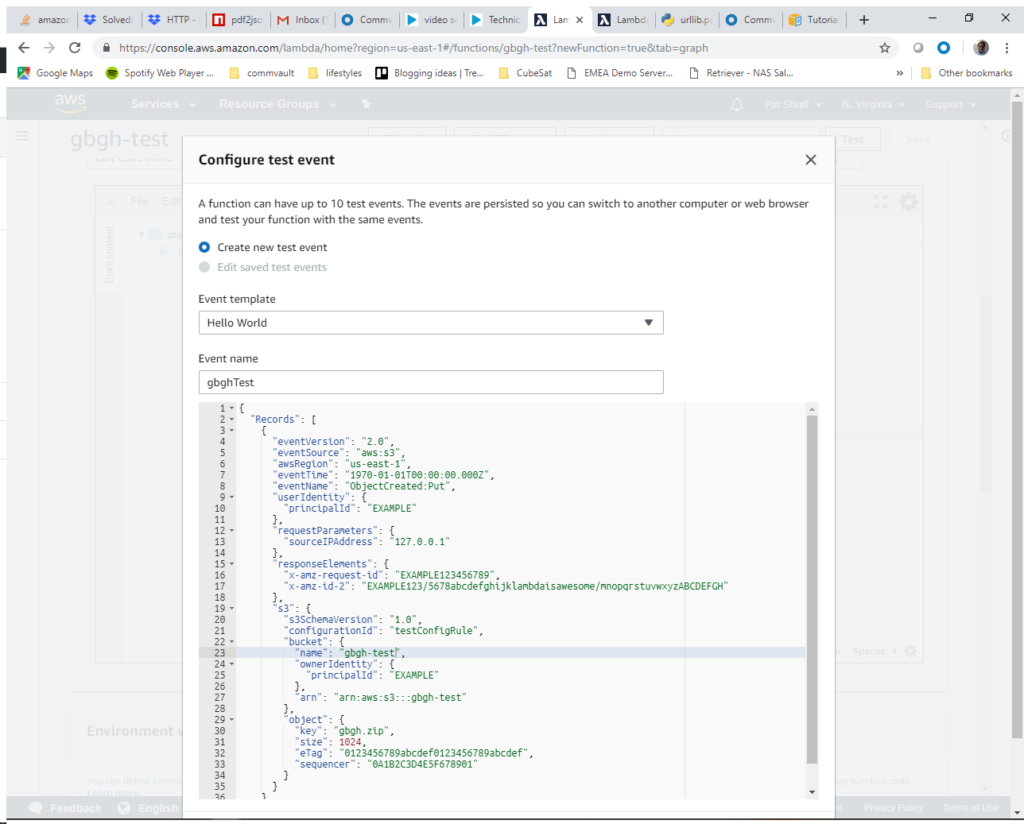
The data at the bottom of the screen are just curly brackets to finish out the record definition. From here we click on Create (I had to scroll down to see it) to create our test function. At this point we can select gbghTest and click on the Test button at the top right of the screen. When we first tried this it failed with an error. We had to add two lines to import the json and urllib functions since we call them to process the keys or object names. Once we make these changes we see that the status came back Succeeded and we get an empty listing of gbgh-test if we scroll down in the Execution results screen.
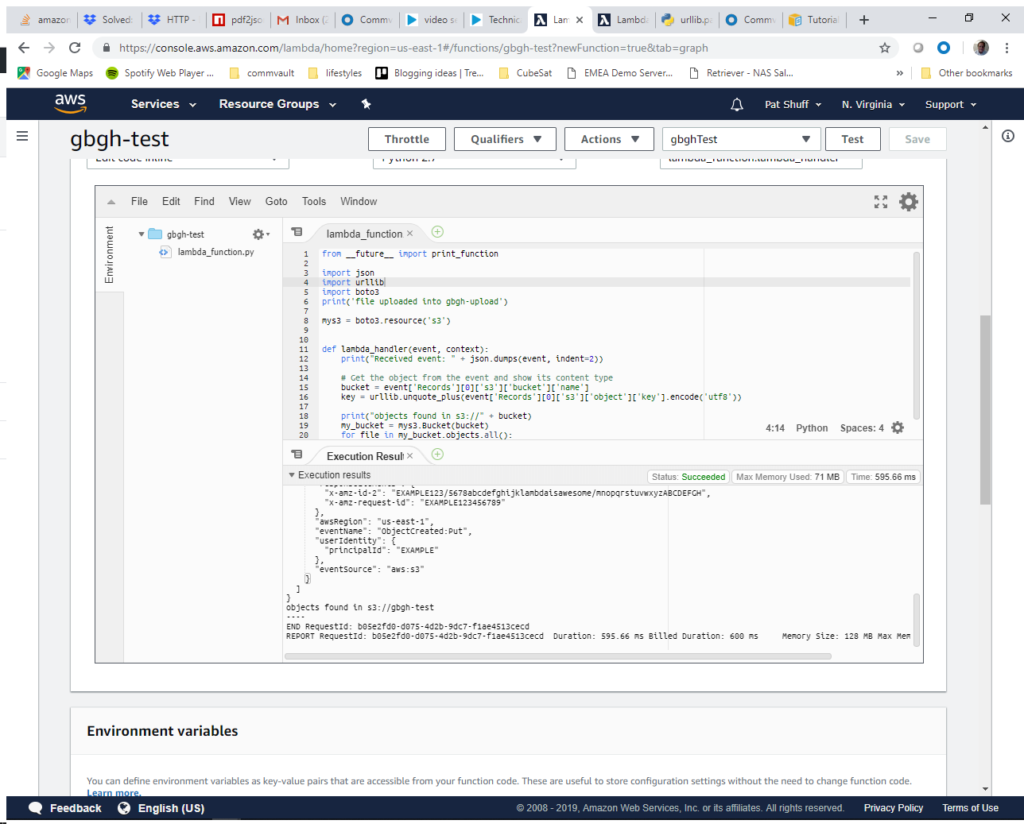
We can upload our gbgh.zip file into our gbgh-test bucket and it should appear at the bottom of the Execution results screen.
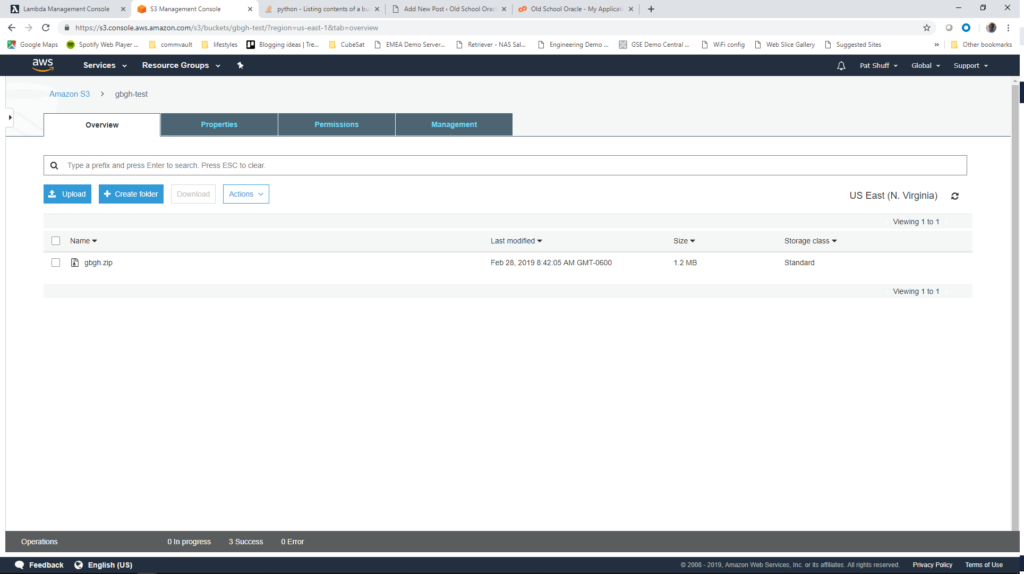
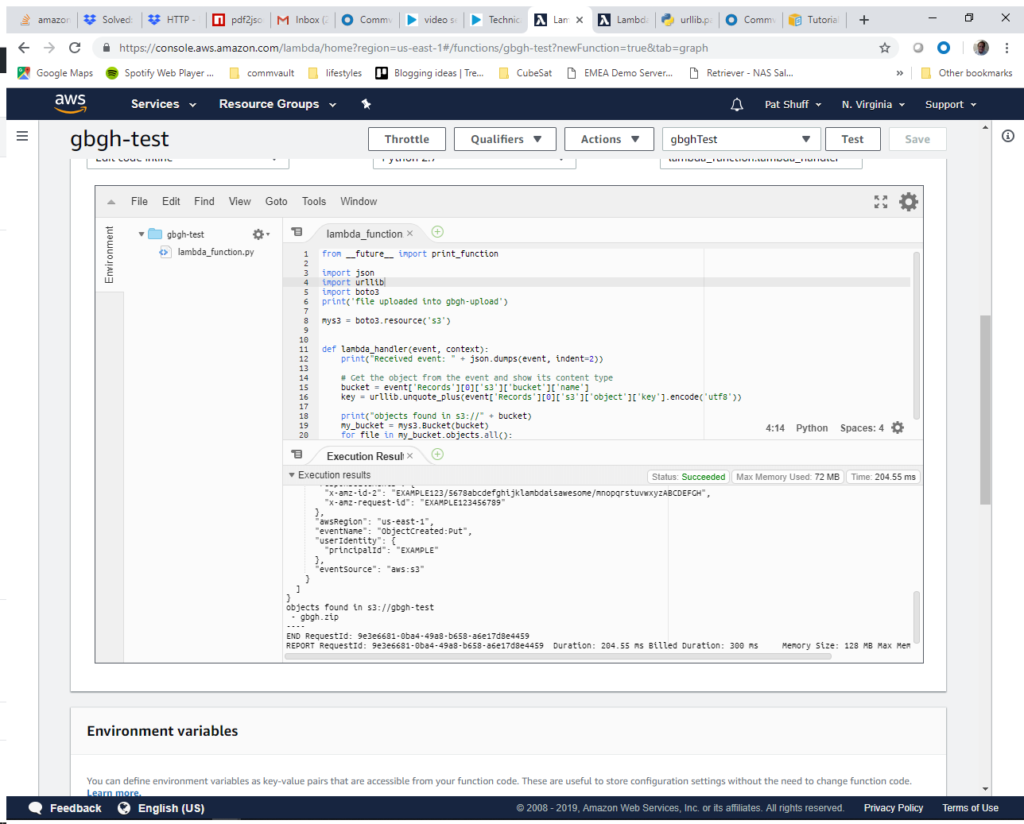
To summarize, we have a Lambda function that gets launched when we upload a file into an S3 bucket. Currently the function just prints a directory of the bucket by listing all of the objects that it contains. We had to create an IAM policy so that our function can interact with S3. In the next blog post we will do some processing of this zip file and send some notifications once the zip file is processed.