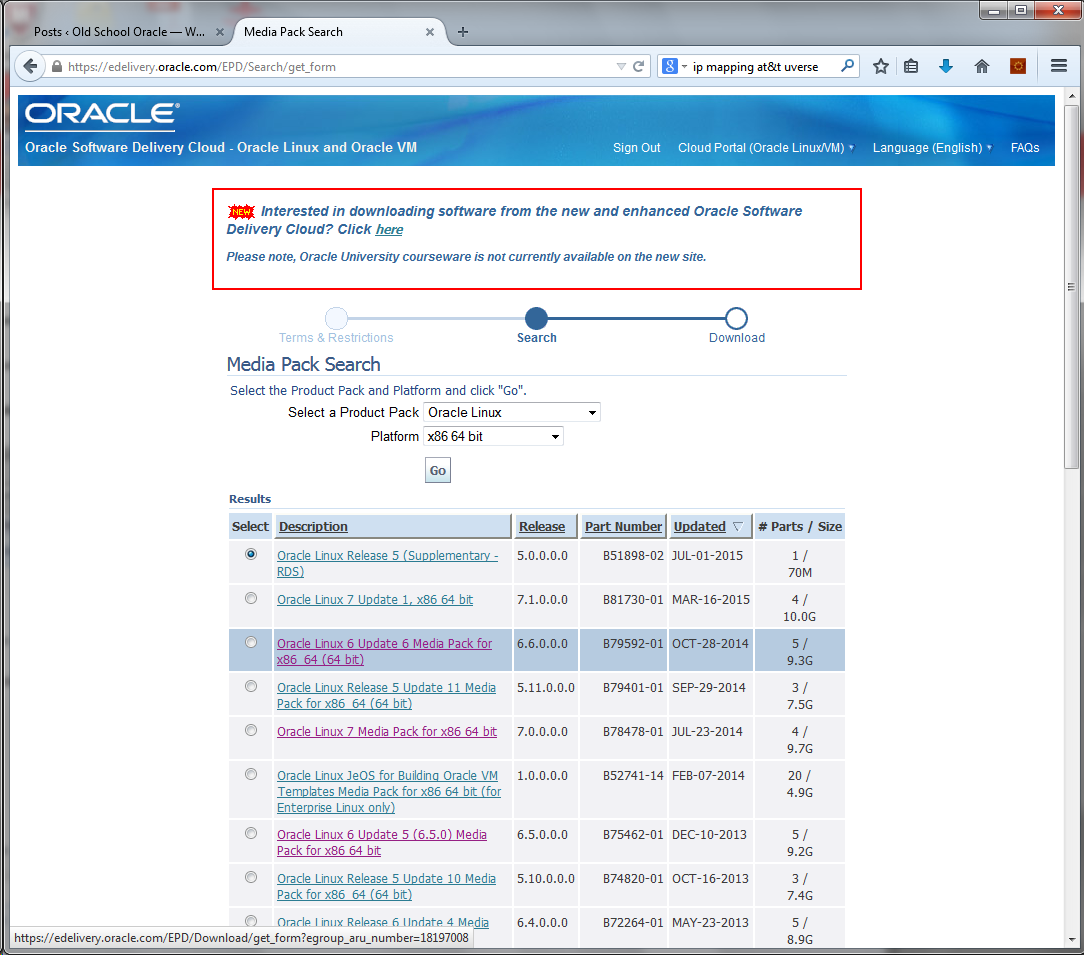
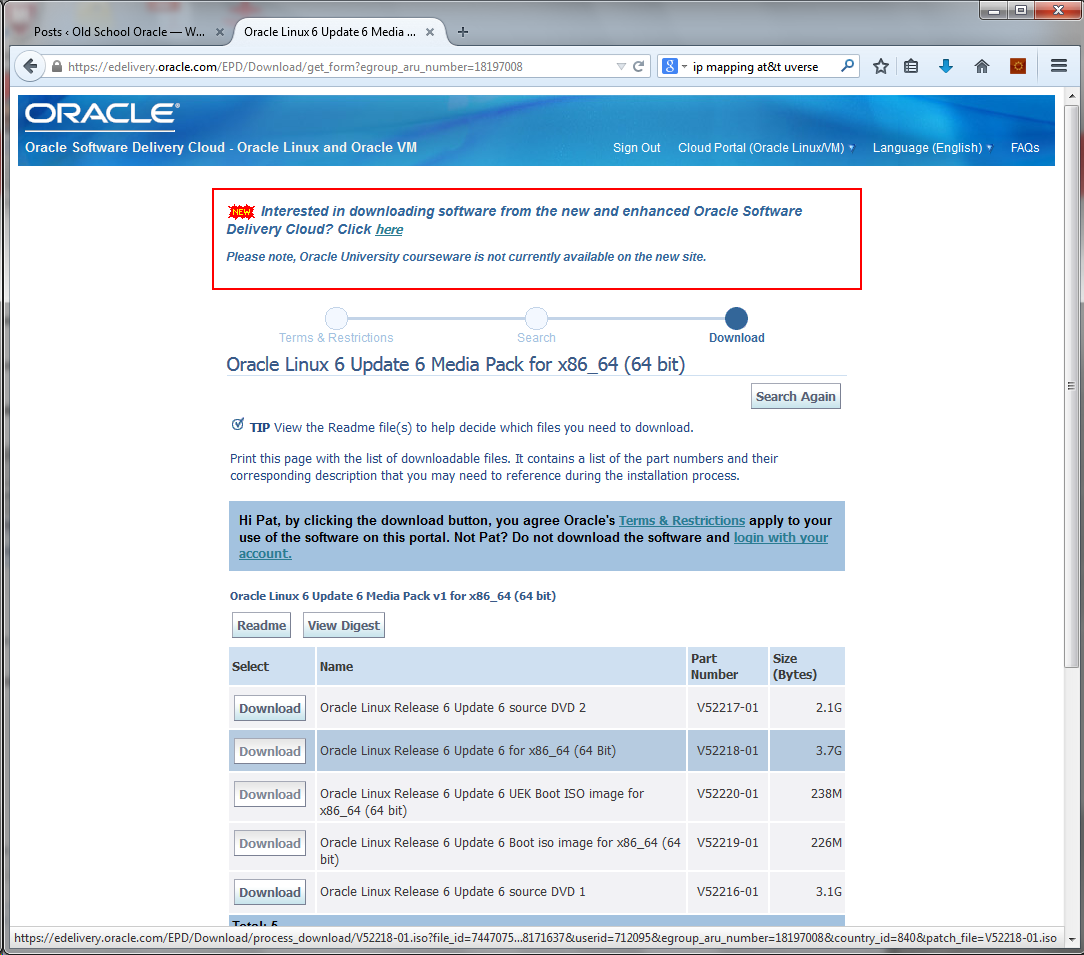
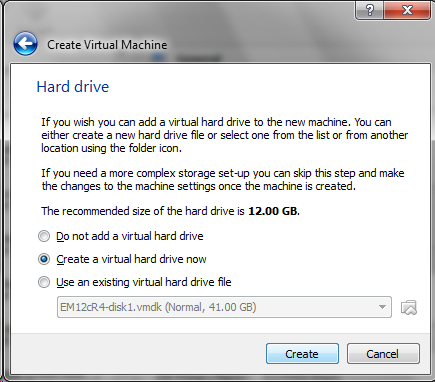
Today we will look at what it takes to turn on and off a light that is not part of the Raspberry Pi. The LEDs have changed between the Pi4 and Pi5 so we will not look at using the on-board LEDs but an LED attached through the GPIO (General Purpose I/O) ports.
Before we get into the GPIO pin assignments, let’s review what an LED is and how it works. If you read the blog posting on driving an LED using an Arduino UNO R3 you can skip to the picture of the Raspberry Pi GPIO ports.
The LED design is very simple. When you put a voltage across an LED it emits light. Unfortunately, if you put 5 volts with almost any amperage across the LED it will melt and become unusable. To prevent the LED from melting a resistor is typically placed between the Raspberry Pi and the LED to limit the voltage going into the LED.
To begin our discussion let’s look at an electrical schematic of an LED.

When a voltage is places across the LED it emits light. The long leg of the LED is the positive lead and the short leg is the negative lead. Putting a positive voltage on the negative lead and grounding the positive lead will not do anything. Putting a positive voltage on the positive lead and grounding the negative lead will cause the LED to “light up” and emit light.
It is important to note that different LEDs require different voltages to emit light. The higher the voltage, the brighter the light shines. A red LED, for example, needs at least 1.63 volts before it begins emitting light and will burn out if you put more than 2.03 volts across it. A green LED, on the other hand needs at least 1.9 volts and can go as high as 4.0 volts before it overheats.

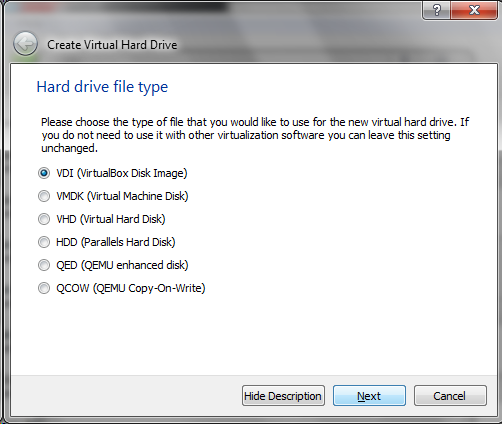
Fortunately, we can use a resistor in series with the LED to control the brightness. The higher the resistor value, the less light the LED will emit. In the picture below a yellow LED is combined with different resistor values.

Note that a 330 Ohm resistor, which has the least amount of resistance of all resistors shown, caused the LED to be brighter. The 100K Ohm resistor, which is about 1000 times more powerful than a 300 Ohm resistor, barely causes the yellow LED to turn on. Note in this diagram the red wire coming in from the left is supplying a 5 volt DC power and the black wire is providing a ground connection. With the breadboard (the white board that everything is plugged into) the two outer rows provide a connection to all of the holes along the blue line. The ground line is the row on the right of the board and the 5 volt line in the next row in line designated with a red stripe

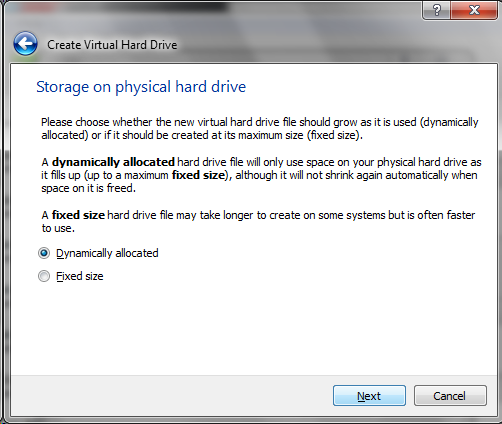
In the diagram above a 220 Ohm resistor is used to limit the voltage going across the green LED. We put 3.3 volts on the red bus on the left and ground on the blue bus on the right. By putting a resistor in hole 17 on the red bus, it connects one end of the resistor to the 3.3 volt supply. By putting the other end of the resistor in the left most pin in row 16 we can then put the positive lead of the LED in any of the holes on row 16 to connect the resistor to the LED. We then put the negative end of the LED in tow 16 on the other side of the air gap and tie it to ground with a wire running from any of the 16 pin holes to any pin on the blue line running up and down. Off screen we connect a voltage supply (or battery) to the red and blue lines with wires somewhere on the breadboard.
To calculate the resistor needed for an LED, we need to know the voltage drop across the LED and the voltage of our supply. For an Raspberry Pi the voltage supply is 5 volts.

To calculate the resistor value we use Ohm’s Law which basically is voltage is the product of current and resistance. If we have multiple voltage drops (as with a resistor and an led in series) the equation to calculate the resistance can be expressed as …

A good website to calculate this is available at https://ohmslawcalculator.com/led-resistor-calculator . If we assume a 5 volt source and a 2 volt drop across the LED with 1 milliamp of current going through the LED and resistor we get a 3000 Ohm resistor (otherwise known as a 3K resistor). If we have a 4 volt drop (as is the case with a green LED) we would use a 1K resistor. In this example we would place a 3K resistor in series with a red LED and a 1K resistor in series with a green LED to have them with the same brightness. It is important to note that putting the resistor closer to the 5 volt power or closer to the ground line makes no difference. The only important thing is to put the resistor in series with the LED which means that they share one common plug in point on the breadboard.

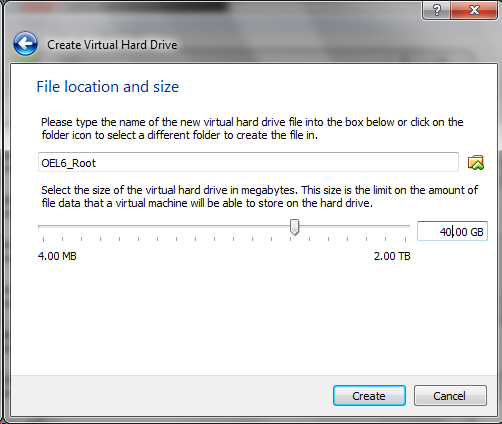
In the above diagram the blue wire is attached to ground on the Raspberry Pi and the purple wire is attached to GPIO pin 14. For the Raspberry Pi 5 the GPIO pinout is the same as previous versions of the Raspberry Pi.

Note that the GPIO lines are arranged on both sides of the connector block and are numbered from 0 through 27. Some of these pins have special functions like pulse width modulation (PWM) or serial transmission (TXD/RXD) while others are generic input and output pins. Pins 5, 6, 16, 17, 22, 23, 24, 25, 26, and 27 are generic pins and can be programmed to be digital input or output lines. When a line is programmed to be an output line it is either enabled to be HIGH (or 5 volts) or LOW (or zero volts).
Let’s start by driving one LED using GPIO pin 17 as shown in the diagram

In this example we are going to use the command line to turn on and off the LED. To do this we will ssh into the Raspberry Pi and execute the pinctrl command. This command allows us to set a pin high or low with a simple command.
$ pinctrl set 17 op
defined GPIO pin 17 as an output pin
$ pinctrl set 17 dh
turns on the LED by driving GPIO pin 17 with 5 volts.
$ pinctrl set 17 dl
turns off the LED by driving GPIO pin 17 to zero volts.
We can program this in a shell command by creating an infinite loop, turning on the LED, sleeping for a while, turning off the LED, and sleeping again before repeating
pinctrl set 17 op
while true
do
pinctrl set 17 dh
sleep 1
pinctrl set 17 dl
sleep 1
done
The first pinctrl command defined GPIO pin 17 as an output only pin. The while true creates the infinite loop. Everything between the do and done statements will be executed over and over. The second pinctrl command sets pin 17 to high with the dh option. The sleep 1 sleeps for a full second. The third pinctrl command sets pin 17 to low followed by another sleep function for another second.
We could change this program to drive multiple LEDs of different colors as is done with a traffic light by using multiple GPIO pins.

In this example we are driving the Red LED with GPIO pin 17, the yellow with pin 18, and the green with pin 22 (with an extra blue LED on pin 23). We can change the code by repeating the pinctrl commands directing the different pins to turn on and off the lights
# define GPIO pins as outputs
pinctrl set 17 op # Red LED
pinctrl set 18 op # yellow LED
pinctrl set 22 op # green LED
pinctrl set 23 op # blue LED
#
# loop through turning on and off lights
while true
do
pinctrl set 17 dh # turn on red LED
sleep 1
pinctrl set 17 dl # turn off red LED
sleep 1
pinctrl set 18 dh # turn on yellow LED
sleep 1
pinctrl set 18 dl # turn off yellow LED
sleep 1
pinctrl set 22 dh # turn on green LED
sleep 1
pinctrl set 22 dl
sleep 1
done
The lines in red are the added lines to drive the two additional LEDs. Using the command line can have some difficulties and is not the best way of performing this operation. To perform the pinctrl command you might need to be a root or super user. Not everyone has the rights or privileges to perform this function. In the next post we will look at using a programming language rather than a command line to drive the LEDs.