In a previous post we talked about the vsphere provider and what is needed to define a connection to create a virtual machine. In this blog we will start to look at what is needed to setup a similar environment to do the same thing in AWS EC2. Think of it as a design challenge. Your client comes to you and says “I want a LAMP or WAMP stack or Tomcat Server that I can play with. I want one local as well as one in the cloud. Can you make that happen?”. You look around and find out that they do have a vSphere server and figure out how to log into it and create a Linux instance to build a LAMP stack and a Windows instance to create a WAMP stack then want to repeat this same configuration in AWS, Azure, and/or Google GCP. Simple, right?
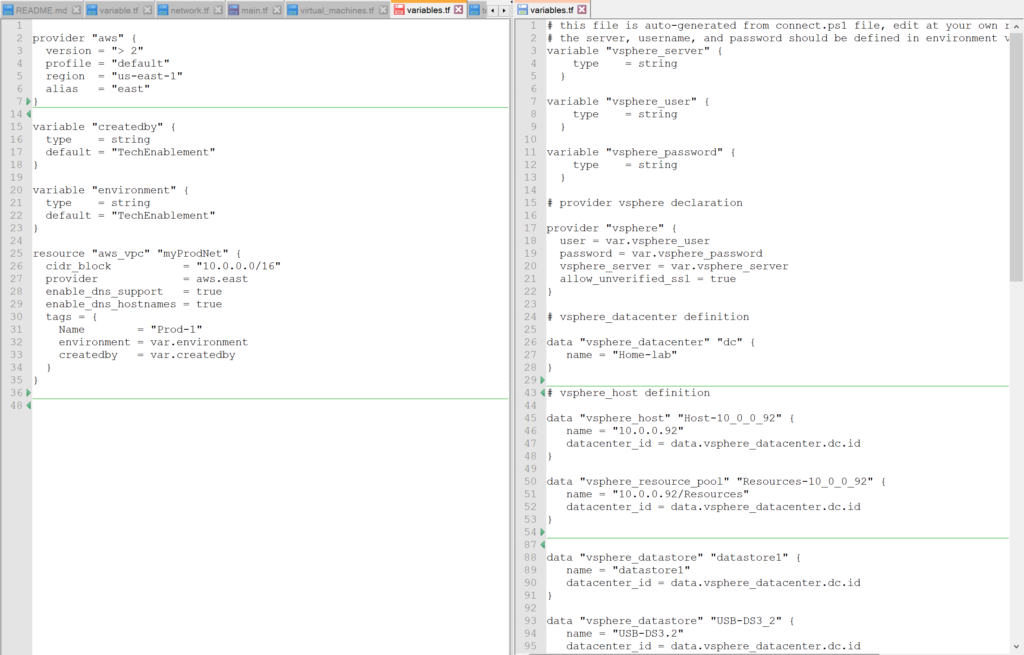
If you remember, to create a vSphere provider declaration in Terraform you basically need a username, password, and IP address of the vSphere server.
provider “vsphere” {
user = var.vsphere_user
password = var.vsphere_password
vsphere_server = var.vsphere_server
version = “1.12.0”
allow_unverified_ssl = true
}
The allow_unverified_ssl is to get around that most vSphere installations in a lab don’t have a certified certificate but a self-signed certificate and the version is to help us keep control of syntax changes in our IaC definitions that will soon follow.
The assumptions that you are making when connecting to a vSphere server when you create a virtual machine are
- Networking is setup for you. You can connect to a pre-defined network interface from vSphere but you really can’t change your network configuration beyond what is defined in your vSphere instance.
- Firewalls, subnets, and routing is all defined by a network administrator and you really don’t have control over the configuration inside Terraform unless you manage your switches and routers from Terraform as well. The network is what it is and you can’t really change it. To change routing rules and blocked or open ports on a network typically requires reconfiguration of a switch or network device.
- Disks, memory, and CPUs are limited by server configurations. In my home lab, for example, I have two 24 core servers with 48 GB of RAM on one system and 72 GB of RAM on the other. One system has just under 4 TB of disk while the other has just over 600 GB of disk available.
- Your CPU selection is limited to what is in your lab or datacenter. You might have more than just an x86 processer here and there but the assumption is that everything is x86 based and not Sparc or PowerPC. There might be an ARM processor as an option but not many datacenters have access to this unless they are developing for single board computers or robotics projects. There might be more advanced processors like a GPU or Nvidia graphics accelerated processor but again, these are rare in most small to midsize datacenters.
Declaring a vsphere provider gives you access to all of these assumptions. If you declare an aws or azure provider these assumptions are not true anymore. You have to define your network. You can define your subnet and firewall configurations. You have access to almost unlimited CPU, memory, and disk combinations. You have access to more than just an x86 processor and you have access to multiple datacenters that span the globe rather than just a single cluster of computers that are inside your datacenter.
The key difference between declaring a vsphere provider and an aws provider is that you can declare multiple aws providers and use multiple credentials as well as different regions.
provider “aws” {
version = “> 2”
profile = “default”
region = “us-east-1”
alias = “aws”
}
Note we don’t connect to a server. We don’t have a username or password. We do define a version and have three different parameters that we pass in. So the big question becomes how do we connect and authenticate? Where is this done if not in the provider connection? We could have gotten by with just provider “aws” {} and that would have worked as well.
To authenticate using the Hashicorp aws provider declaration you need to
- declare the access_key and secret_key in the declaration (not advised)
- declare the AWS_ACCESS_KEY_ID and AWS_SECRET_ACCESS_KEY_ID as environment variables
- or point to a configuration file with the shared_credentials_file declaration or AWS_SHARED_CREDENTIALS_FILE environment variable leveraging the profile declaration or PROFILE environment variable.
- automatic loading of the ~/.aws/credentials or ~/.aws/config files
The drawback to using the environment variables is that you can only have one login into your aws console but can connect to multiple regions with the same credentials. If you have multiple accounts you need to declare the access_key and secret_key or the more preferred method of using the shared_credentials_file declaration.
For the aws provider, all parameters are optional. The provider is flexible enough to make some assumptions and connect to AWS based on environment variables and optional parameters defined. If something is defined with a parameter it is used over the environment variable. If you define both a key and a shared_credentials_file, Terraform will throw an error. If you have environment variables define and a ~/.aws/credentials file, the environment variables will be used first.
If we dive a little deeper into our vsphere variables.tf file we note that we need to run a script or manually generate the declarations for vsphere_datacenter, vsphere_host, and vsphere_resource_pool prior to defining a virtual machine. With the aws provider we only need to define the region to define all of these elements. Unfortunately, we also need to define the networking connections, subnet definitions, and potential firewall exceptions to be able to access our new virtual machine. It would be nice if we could take our simple vsphere virtual machine definition defined in our vsphere main.tf file and translate it directly into an aws_instance declaration. Unfortunately, there is very little that we can translate from one environment to the other.
The aws provider and aws_instance declaration does not allow us to clone an existing instance. We need to go outside of Terraform and create an AMI to use as a reference for aws_instance creation. We don’t pick a datacenter and resource_pool but select a region to run our instance. We don’t need to define a datastore to host the virtual machine disks but we do need to define the disk type and if it is a high speed (higher cost) or spinning disk (lower cost) to host the operating system or data.
We can’t really take our existing code and run it through a scrubber and spit out aws ready code unfortunately. We need to know how to find a LAMP, WAMP, and Tomcat AMI and reference it. We need to know the network configurations and configure connections to another server like a database or load balancer front end. We also need to know what region to deploy this into and if we can run these services using low cost options like spot instances or can shut off the running instance during times of the day to save money given that a cloud instance charges by the minute or hour and a vsphere instance is just consuming resources that you have already paid for.
One of the nice things about an aws provider declaration is that you can define multiple providers in the same file which generated an error for a vsphere provider. You can reference different regions using an alias. In the declaration shown above we would reference the provider with
provider = aws.aws
If we wanted to declare that the east was our production site and the west was our dev site we could use the declaration
provider “aws” {
version = “> 2”
profile = “default”
region = “us-east-1”
alias = “east”
}
provider “aws” {
version = “> 2”
profile = “default”
region = “us-west-1”
alias = “west”
}
If we add a declaration of a network component (aws_vpc) we can populate our state file and see that the changes were pushed to our aws account.
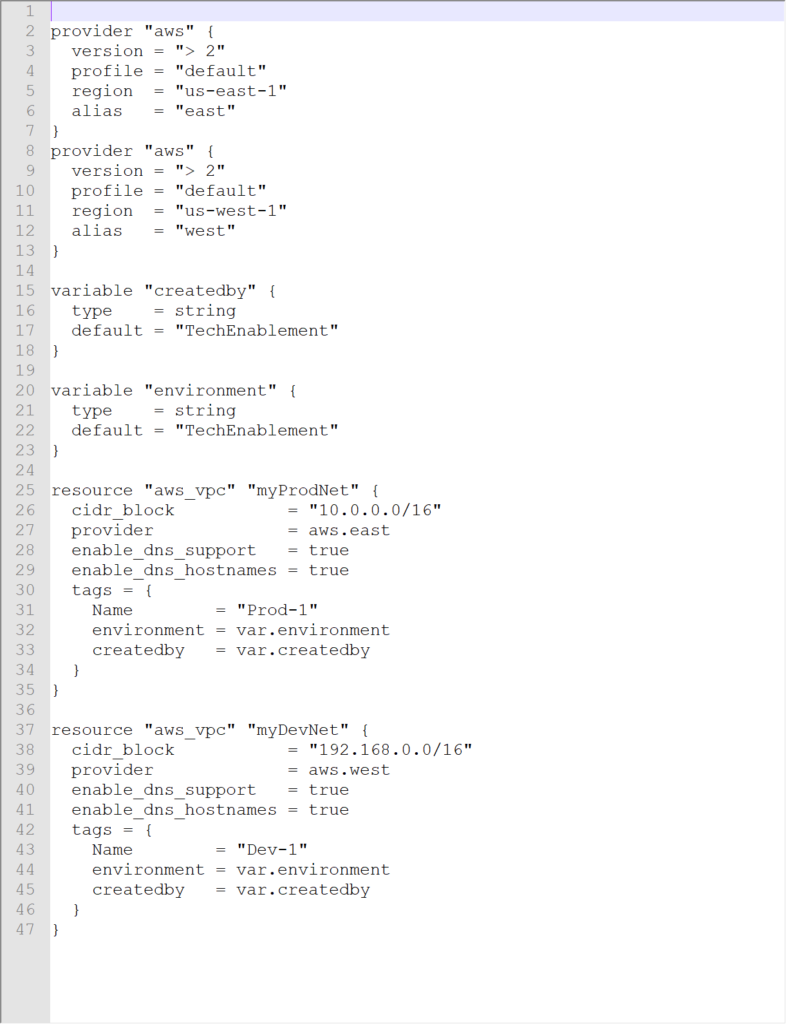
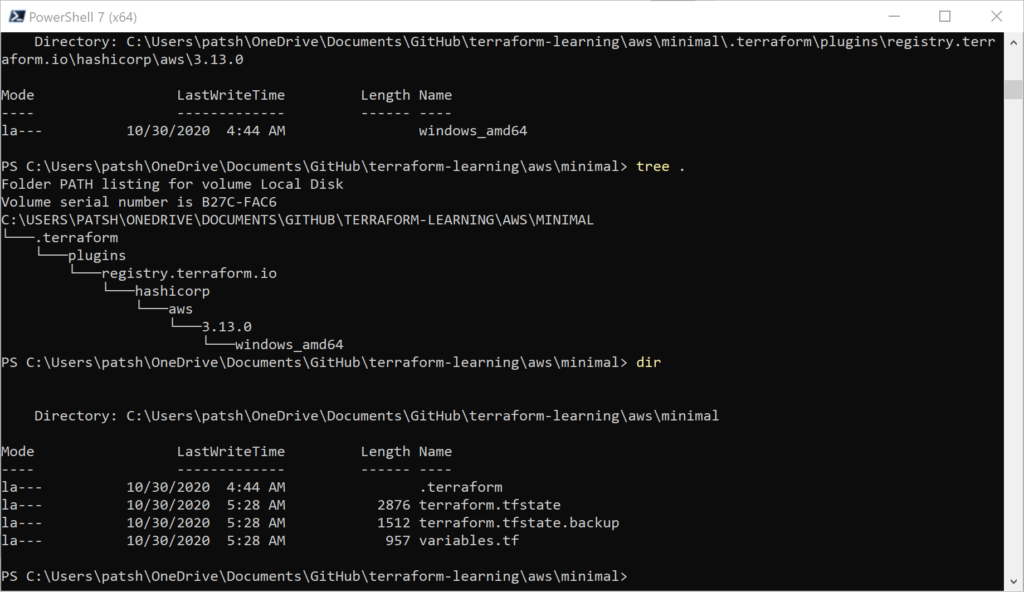
We get the .terraform tree populated for our Windows desktop environment as well as the terraform.tfstate created. Looking at our AWS VPC console we see that Prod-1 was created in US-East-1 (and we could verify that Dev-1 was created in US-West-1 if we wanted).
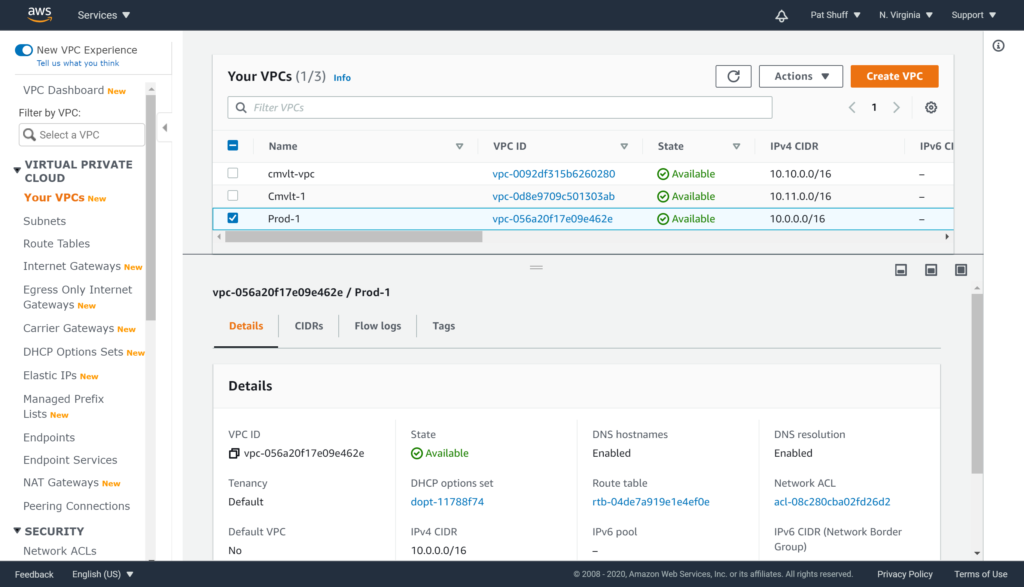
Note that the CIDR block was correctly defined as 10.0.0.0/16 as desired. If we run the terraform destroy command to clean up this vpc will be destroyed since it was created and is controlled by our terraform declaration.
Looking at our terraform state file we can see that we did create two VPC instances in AWS and the VPC ID should correspond to what we see in the AWS console.
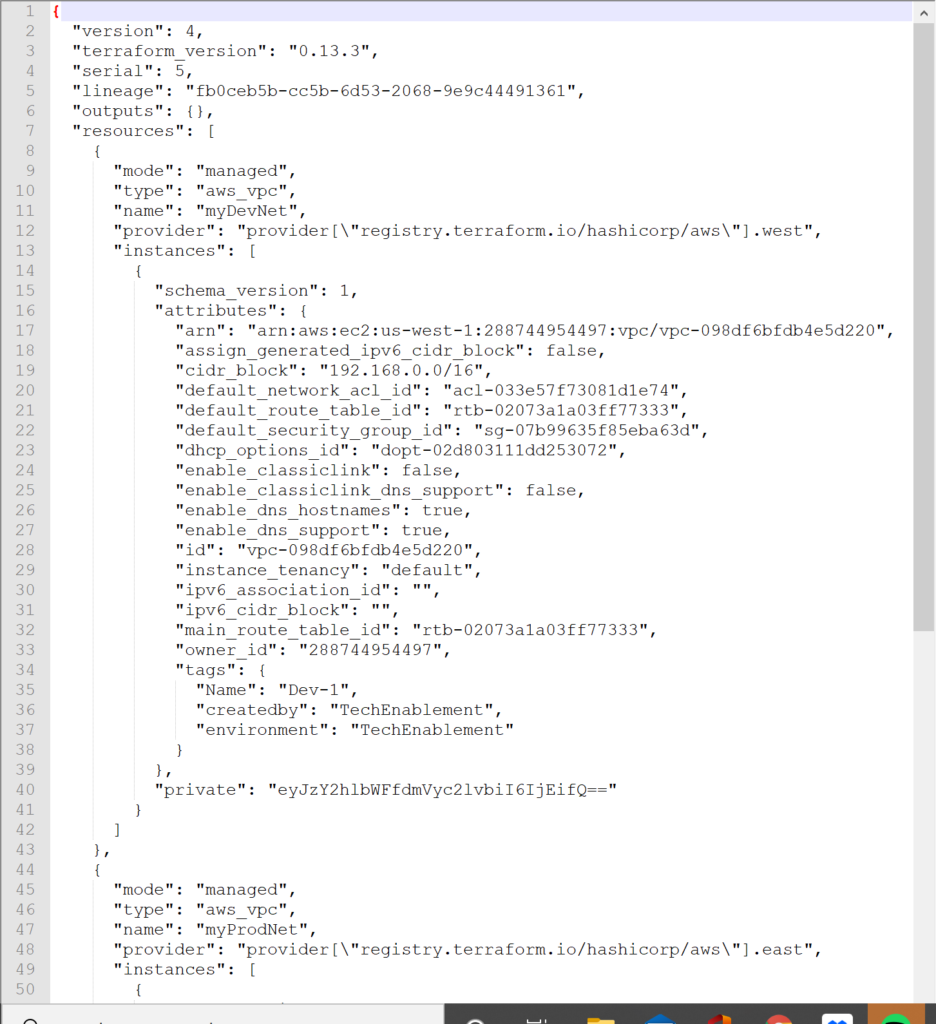
In summary, using Terraform to provision and manage resources in Amazon AWS is somewhat easier and somewhat harder than provisioning resources in a vSphere environment. Unfortunately, you can’t take a variables.tf or main.tf declaration from vSphere and massage it to become a AWS definition. The code needs to be rewritten and created using different questions and parameters. You don’t need to get down to the SCSI target level with AWS but you do need to define the network connection and where and how the resource will be declared with a finer resolution. You can’t clone an existing machine inside of Terraform but you can do it leveraging private AMI declarations in AWS similar to the way that templates are created in vSphere. Overall an AWS managed state with Terraform is easy to start and allows you to create a similar environment to an on-premises environment as long as you understand the differences and cost implications between the two. Note that the aws provider declaration is much simpler and cleaner than the vsphere provider. Less is needed to define the foundation but more is needed as far as networking and how to create a virtual instance with AMIs rather than cloning.
The variables.tf and terraform.state files are available on github to review.
Service Unavailable
The server is temporarily unable to service your request due to maintenance downtime or capacity problems. Please try again later.
Additionally, a 503 Service Unavailable error was encountered while trying to use an ErrorDocument to handle the request.