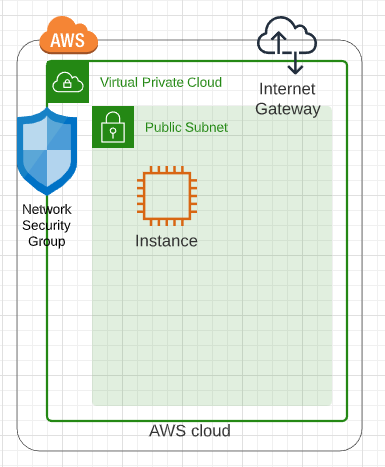
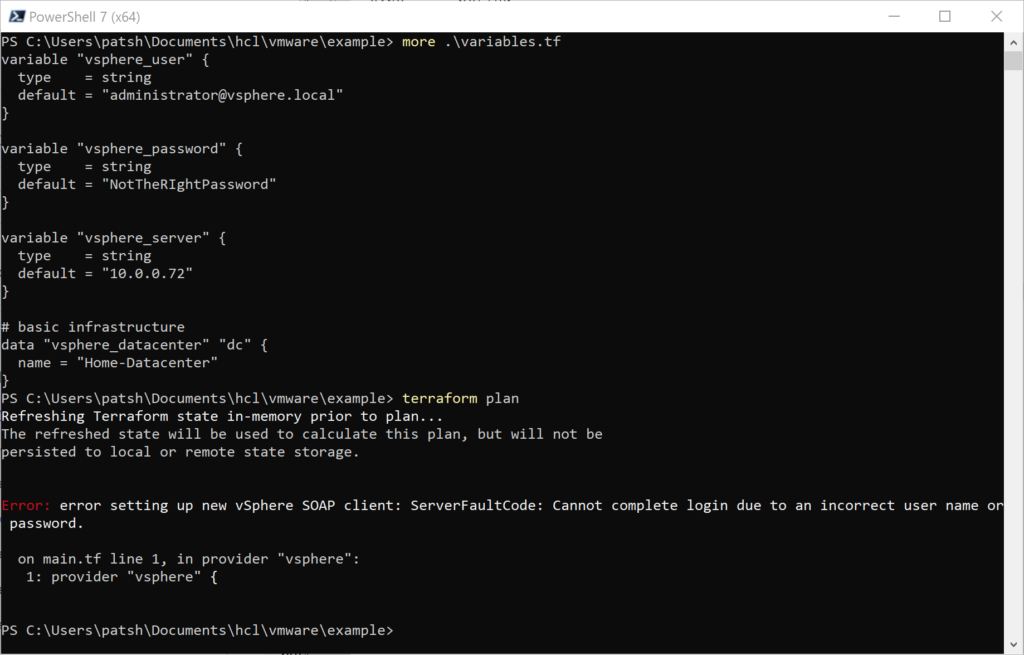
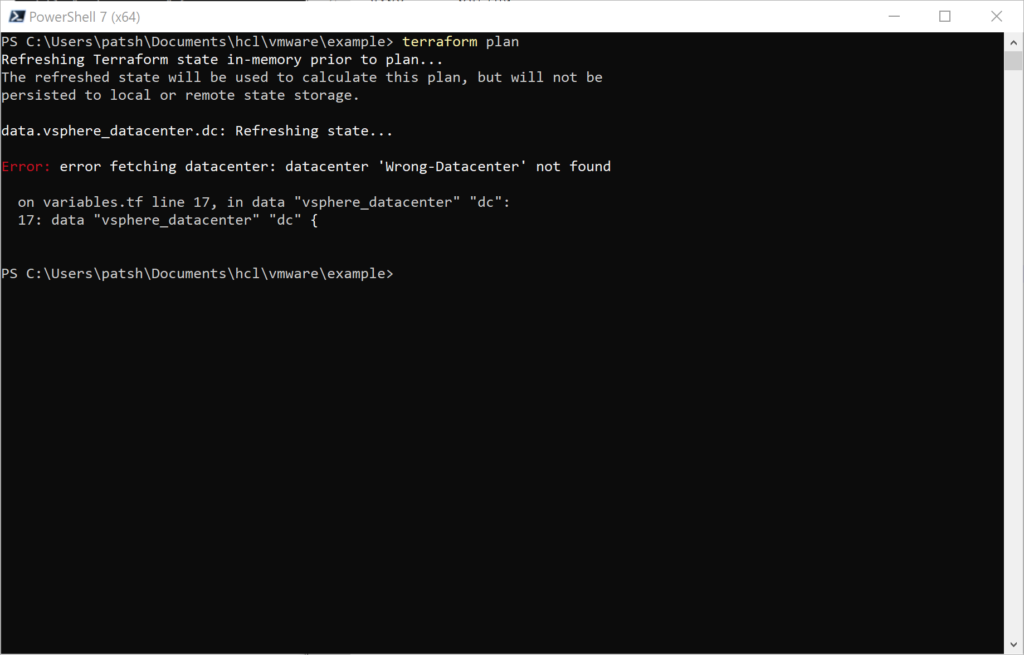
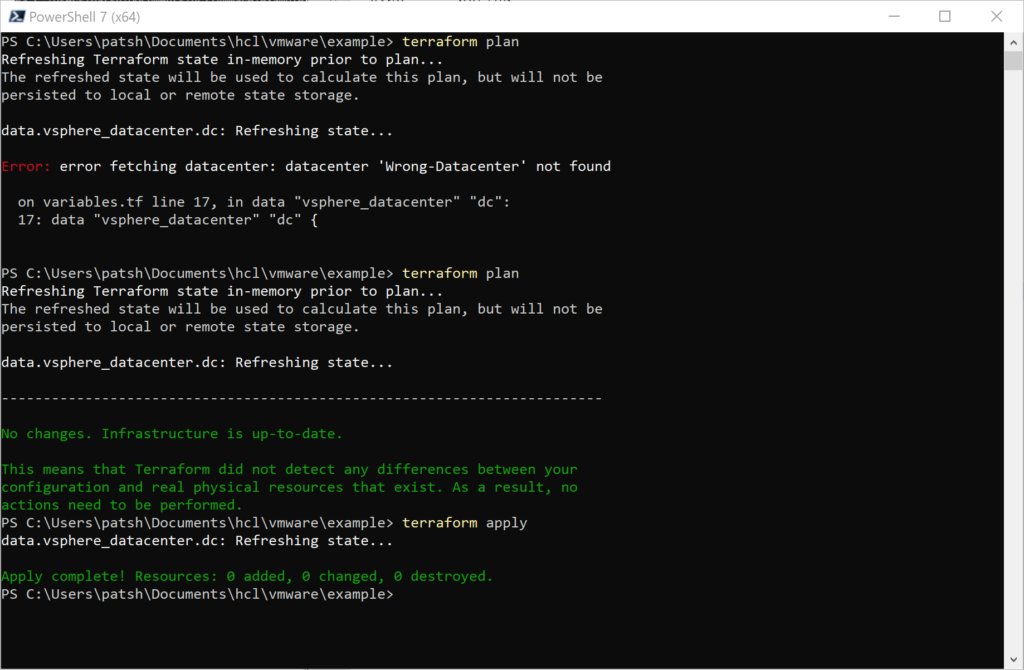
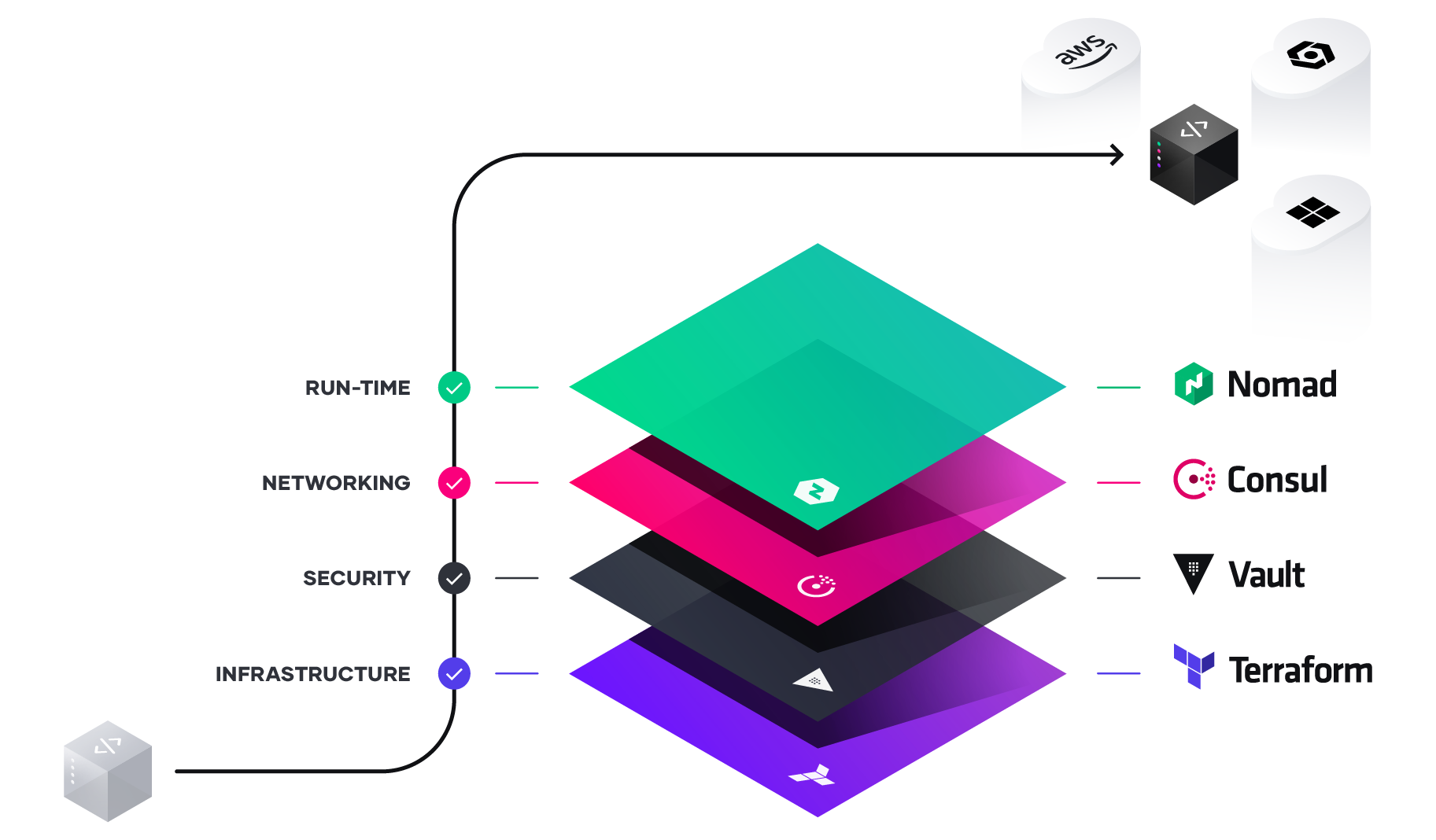
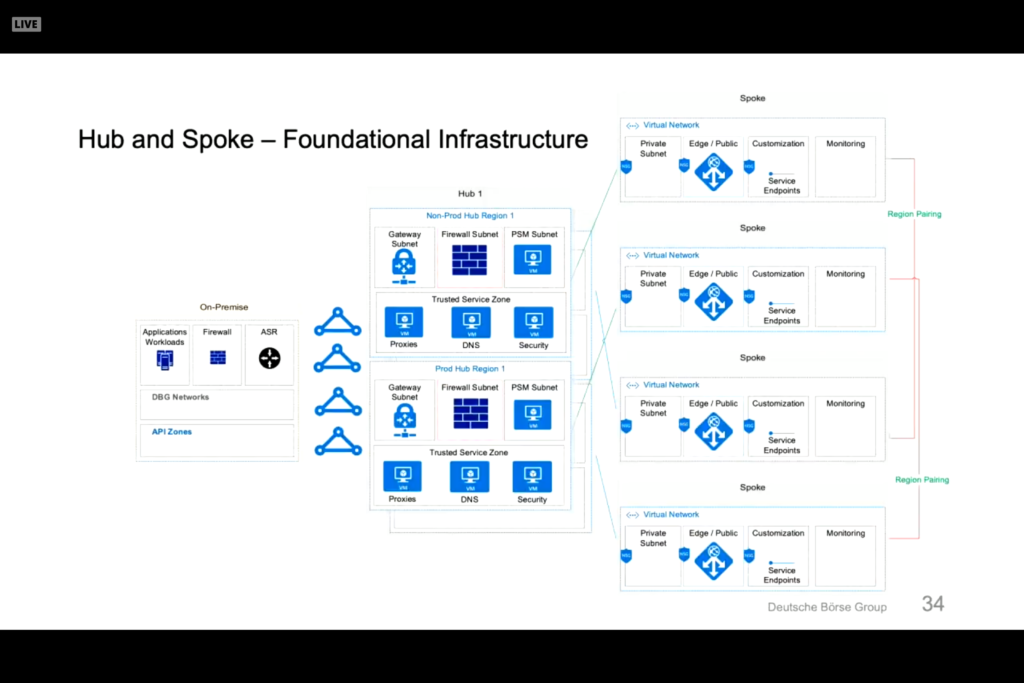
In a previous post we looked at network requirements required to deploy an instance in AWS. In this post we are going to look at what it takes to pull a Marketplace Amazon Machine Instance (AMI) from the marketplace and deploy it into a virtual private cloud with the appropriate network security group and subnet definitions.
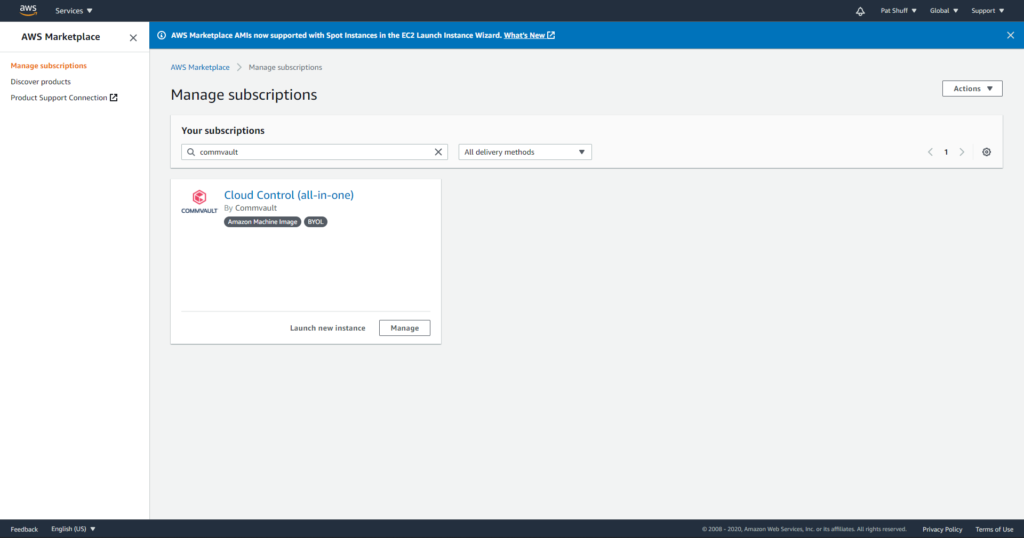
If you go into the AWS Marketplace from the AWS Console you get a list of virtual machine images. We are going to deploy a Commvault CommServe server instance because it is relatively complex with networking requirements, SQL Server, IIS Server, and customization after the image is deployed. We could just as easily have done a Windows 2016 Server or Ubuntu 18 Server instance but wanted to do something a little more complex.
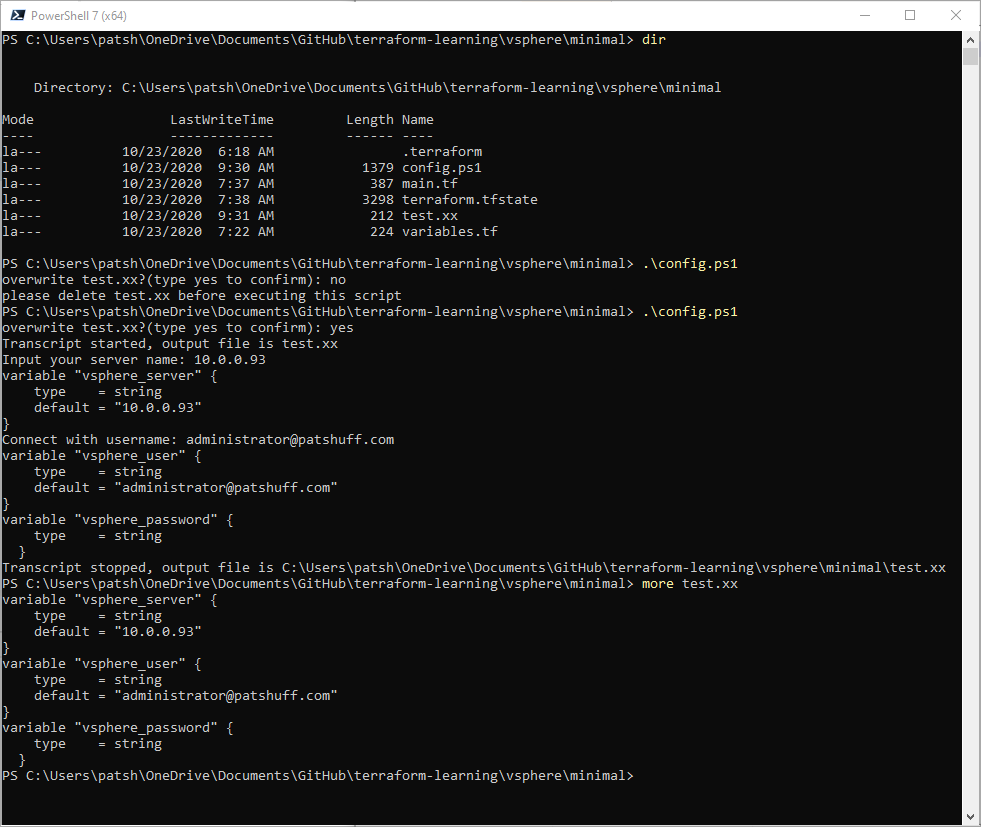
The Cloud Control is a Windows CommServe server installation. The first step needed is to open a PowerShell and connect to Amazon using the aws command line interface. This might require an Install-Module aws to get the aws command line installed and configured but once it is ready to connect to aws by typing in
aws configure
We can search for Marketplace images by doing an ec2 describe-images with a filter option
aws ec2 describe-images –executable-users all –filters “Name=name,Values=*Cloud Control*”
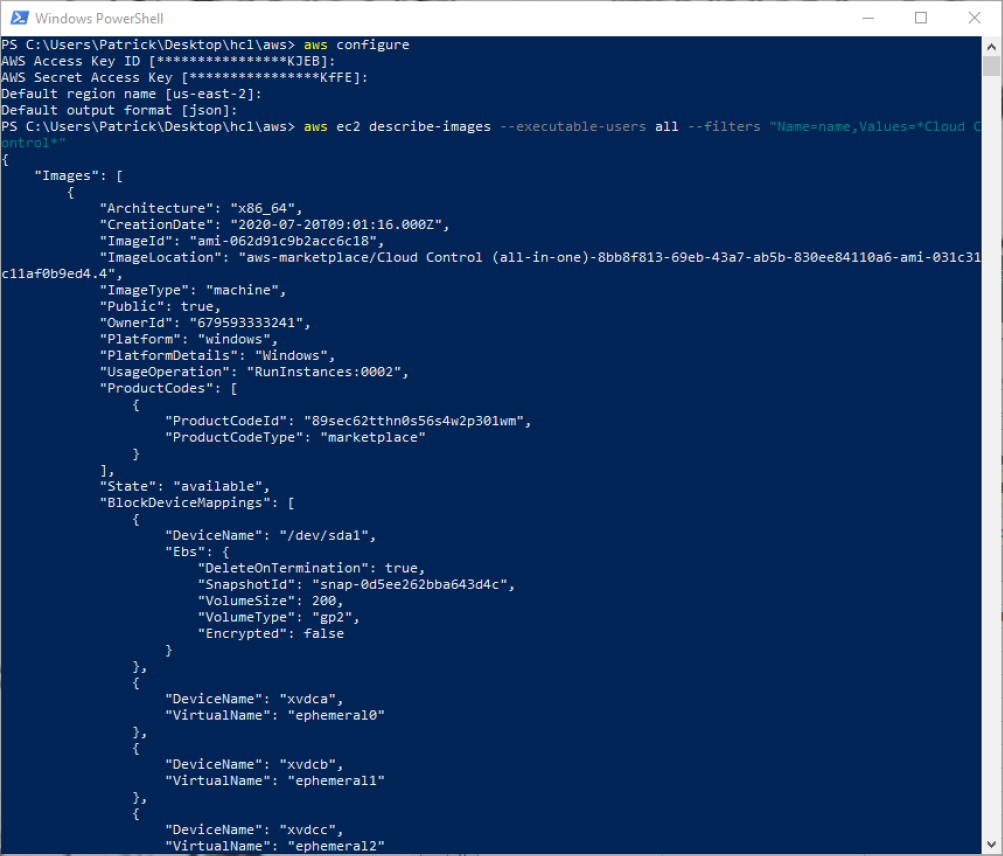
The describe-images command searches for an Amazon AMI that matches the description that we are looking for and returns an AMI ID. From this we can create a new instance pre-configured with a CommServe server. From here we can create out terraform files. It is important to note that the previous examples of main.tf and network.tf files do not need to be changed for this definition. We only need to create a virtual_machine.tf file to define our instance and have it created with the network configurations that we have previously defined.
We will need to create a new variable in our main.tf file that defines the private and public key that we are going to use to authenticate against our Windows server.
resource “aws_key_pair” “cmvlt2020” {
provider = aws.east
key_name = “cmvlt2020”
public_key = “AAAAB3NzaC1yc2EAAAADAQABAAABAQCtVZ7lZfbH8ZKC72A+ipNB6L/upQrj8pRxLwzQi7LVPrameil8/q4ROvWbC1KC9A3Ego”
}
A second element that needs to be defined is an aws_ami data declaration to reference an existing AMI. This can be done in the virtual_machines.tf file to isolate the variable and data declaration for virtual machine specific definitions. If we wanted to define an Ubuntu instance we would need to define the owner as well as the filter to use for an aws_ami search. In this example we are going to look for Ubuntu on an AMD 64-bit processor. The unusualness is the owners that needs to be used for Ubuntu since it is controlled by a third part Marketplace owner.
variable “ubuntu-version” {
type = string
default = “bionic”
# default = “xenial”
# default = “groovy”
# default = “focal”
# default = “trusty”
}
data “aws_ami” “ubuntu” {
provider = aws.east
most_recent = true
# owners = [“Canonical”]
owners = [“099720109477”]
filter {
name = “name”
values = [“ubuntu/images/hvm-ssd/ubuntu-${var.ubuntu-version}–amd64-server-“]
}
}
output “Ubuntu_image_name” {
value = “${data.aws_ami.ubuntu.name}”
}
output “Ubuntu_image_id” {
value = “${data.aws_ami.ubuntu.id}”
}
In this example we will be pulling the ubuntu-bionic-amd64-server image that has hardware virtualization running on a solid state disk. The variable ubuntu-version is mapped to the version of the Ubuntu kernel that is desired. The filter.values does the search in the Marketplace store to find the AMI ID. We restrict the search by searching in the region that we are deploying and use owner “099720109477” as the Marketplace provider.
If we compare this to a CentOS deployment the centos-version variable has a different string definition and a different owner.
variable “centos-version” {
type = string
default = “Linux 7 x86_64”
# default = “Linux 6 x86_64”
}
data “aws_ami” “centos” {
provider = aws.east
most_recent = true
owners = [“aws-marketplace”]
filter {
name = “name”
values = [“CentOS ${var.centos-version}*”]
}
}
output “CentOS_image_name” {
value = “${data.aws_ami.centos.name}”
}
output “CentOS_image_id” {
value = “${data.aws_ami.centos.id}”
}
For CentOS we can deploy 6 or version 7 by changing the centos-version.default definition. It is important to note that the owner of this AMI is not Amazon and uses the aws-marketplace definition to perform the filter. The same is true for the Commvault image that we are looking at.
data “aws_ami” “commvault” {
provider = aws.east
most_recent = true
# owners = [“Canonical”]
owners = [“aws-marketplace”]
filter {
name = “name”
values = [“*Cloud Control*”]
}
}
output “Commvault_CommServe_image_name” {
value = “${data.aws_ami.commvault.name}”
}
output “Commvault_CommServe_image_id” {
value = “${data.aws_ami.amazon.id}”
}
Note the filter uses a leading wildcard with the name “Cloud Control” followed by a wildcard to look for the instance that we are looking for. Once we have the AMI we can use the AMI.id from our search to define the aws_instance definition.
resource “aws_instance” “commserve” {
provider = aws.east
ami = data.aws_ami.commvault.id
associate_public_ip_address = true
instance_type = “m5.xlarge”
key_name = “cmvlt2020”
vpc_security_group_ids = [aws_security_group.cmvltRules.id]
subnet_id = aws_subnet.mySubnet.id
tags = {
Name = “TechEnablement test”
environment = var.environment
createdby = var.createdby
}
}
output “test_instance” {
value = aws_instance.commserve.public_ip
}
If we take the aws_instance declaration piece by piece the provider defines which AWS region that we will provision into Amazon. The vpc_security_group_ids and subnet_id defines what network that this instance will join. The new declarations are
- ami – AWS AMI id to use as the source to clone
- associate_public_ip_address – do we want a public or private only IP address with this instance
- instance_type – this is the size. We need to reference the documentation or our users to figure out how large or how small this server needs to be. From the Commvault documentation the smallest recommended size is an m5.xlarge.
- key_name – this is the public and private key names that will be used to connect to the Windows instance.
The remainder of the variables like disk, is this a Windows instance, and all the regular required parameters we saw with a vsphere_virtual_machine are provided by the AMI definition.
With these files we can execute from the following files
- aws configure
- terraform init
- terraform plan
- terraform apply
In summary, pulling an AMI ID from the marketplace works well and allows us to dynamically create virtual machines from current or previous builds. The terraform apply finishes quickly but the actual spin up of the Windows instance takes a little longer. Using Marketplace instances like the Commvault AMI provides a good foundation for a proof of concept or demo platform. The files used in this example are available in github.com.